Najważniejsze informacje w skrócie
- Maszyna stanów porządkuje logikę, gdy obiekt ma kilka wyraźnych stanów i ograniczone przejścia między nimi.
- Największą korzyść daje tam, gdzie zachowanie zależy od zdarzeń, a nie od jednego prostego warunku.
- W dobrze zaprojektowanym rozwiązaniu legalne i nielegalne przejścia są jawne, więc łatwiej testować system i szybciej wychwycić błędy.
- To dobry wybór dla procesów takich jak logowanie, checkout, upload plików, workflow publikacji czy obsługa zamówień.
- Nie warto go stosować do prostych przypadków, w których kilka warunków da się czytelnie obsłużyć zwykłą logiką.
- Największe ryzyko to rozrost liczby stanów i ukrycie przejść w wielu miejscach kodu.
Czym jest wzorzec stanów i jak działa
Najprościej ujmując, wzorzec stanów opisuje obiekt, którego zachowanie zmienia się wraz z jego bieżącym stanem. Ten sam obiekt może więc w jednym momencie akceptować dane, w innym odrzucać akcję, a jeszcze później przechodzić do kolejnej fazy procesu. Zamiast pisać jeden ogromny blok warunków, rozdzielasz logikę na stany i kontrolowane przejścia między nimi.
To właśnie dlatego ten model tak dobrze pasuje do systemów, w których istnieje ściśle ograniczony zestaw stanów oraz reguły, kiedy można przejść dalej. W praktyce nie chodzi tylko o nazwę, ale o sposób myślenia: stan ma znaczenie, zdarzenie wywołuje zmianę, a przejście powinno być przewidywalne. Gdy to dobrze rozpiszesz, kod staje się bardziej czytelny niż seria warunków rozrzuconych po całym projekcie.
Ważne jest jeszcze jedno rozróżnienie: ludzie często mieszają pojęcie wzorca stanów z ogólną ideą finite state machine. Te pojęcia są bliskie, ale nie zawsze oznaczają dokładnie to samo w implementacji. W praktyce najczęściej chodzi o to samo pytanie: co obiekt może zrobić teraz, a czego jeszcze nie może.
To dobry punkt wyjścia, bo od razu prowadzi do pytania ważniejszego niż definicja: kiedy taki model naprawdę pomaga, a kiedy tylko dokłada ceremoniału.
Kiedy naprawdę upraszcza architekturę
Ja sięgam po ten wzorzec wtedy, gdy zachowanie zależy od kilku jasno nazwanych etapów i nie chcę, żeby reguły walczyły ze sobą w przypadkowych miejscach kodu. Najczęściej chodzi o procesy, które użytkownik widzi jako przepływ: od jednego kroku do drugiego, z warunkami blokującymi lub odblokowującymi dalsze działania. Jeśli potrafisz rozpisać to w formie grafu stanów, to już dobry znak.
| Kiedy to ma sens | Dlaczego pomaga | Typowy przykład |
|---|---|---|
| Jest kilka stanów i jawne przejścia | Unikasz ukrytych zależności i przypadkowych ścieżek | koszyk, zamówienie, płatność |
| Różne stany mają różne zasady | Każdy stan ma własne zachowanie, więc logika nie puchnie | edytowalny szkic, opublikowany wpis, archiwum |
| Trzeba odrzucać nielegalne akcje | System szybciej wykrywa błędy i łatwiej je testować | nie można opublikować niezatwierdzonej treści |
| Proces ma znaczenie biznesowe | Stan staje się elementem domeny, a nie tylko technicznym detalem | rejestracja konta, onboarding, workflow akceptacji |
Odwrotnie jest wtedy, gdy masz tylko dwa proste przypadki i jeden oczywisty warunek. W takich sytuacjach wzorzec potrafi być przerostem formy nad treścią. Zostawiłbym go też na boku, jeśli proces jest długi, wieloetapowy, oparty o zewnętrzne integracje i retry, bo wtedy szybciej zaczynasz myśleć o workflow engine niż o zwykłej maszynie stanów.
Dobry test praktyczny brzmi: czy potrafię nazwać stany i przejścia bez zgadywania? Jeśli tak, warto iść dalej. Jeśli nie, najpierw trzeba doprecyzować domenę, bo dopiero potem ma sens budowa kodu.
Jak zaprojektować go krok po kroku
Najwięcej błędów widziałem nie w kodzie, tylko w źle rozpisanej logice przed kodem. Dlatego zaczynam od prostego schematu: stan, zdarzenie, przejście, efekt uboczny. Gdy te cztery elementy są jasne, implementacja robi się dużo mniej ryzykowna.
- Wypisz wszystkie stany, które są naprawdę potrzebne, bez dopisywania wariantów „na wszelki wypadek”.
- Zdefiniuj zdarzenia, czyli sytuacje, które mogą wywołać zmianę stanu.
- Określ legalne przejścia i zaznacz, czego system ma nie pozwalać zrobić.
- Rozdziel logikę domenową od szczegółów technicznych, na przykład od UI albo warstwy transportu.
- Dodaj akcje wejścia i wyjścia tylko tam, gdzie naprawdę coś zmieniają, na przykład zapis, logowanie albo wysyłkę komunikatu.
- Przetestuj nie tylko „szczęśliwą ścieżkę”, ale też przejścia zabronione.
W praktyce pomaga mi też jedna reguła: stan powinien być nazwą biznesową, nie technicznym odpadem. „pending”, „approved”, „rejected”, „draft” albo „published” są dużo lepsze niż „step1” i „step2”, bo od razu niosą znaczenie. Jeśli nazwa nie mówi nic o domenie, to zwykle znaczy, że model jest jeszcze niedojrzały.
Na tym etapie warto też zdecydować, kto jest właścicielem przejścia. Czasem to sam obiekt zmienia swój stan, czasem robi to osobny serwis, a czasem masz centralny dispatcher zdarzeń. Każde z tych podejść może być poprawne, ale mieszanie ich bez planu kończy się chaosem, który trudno później testować i rozwijać.
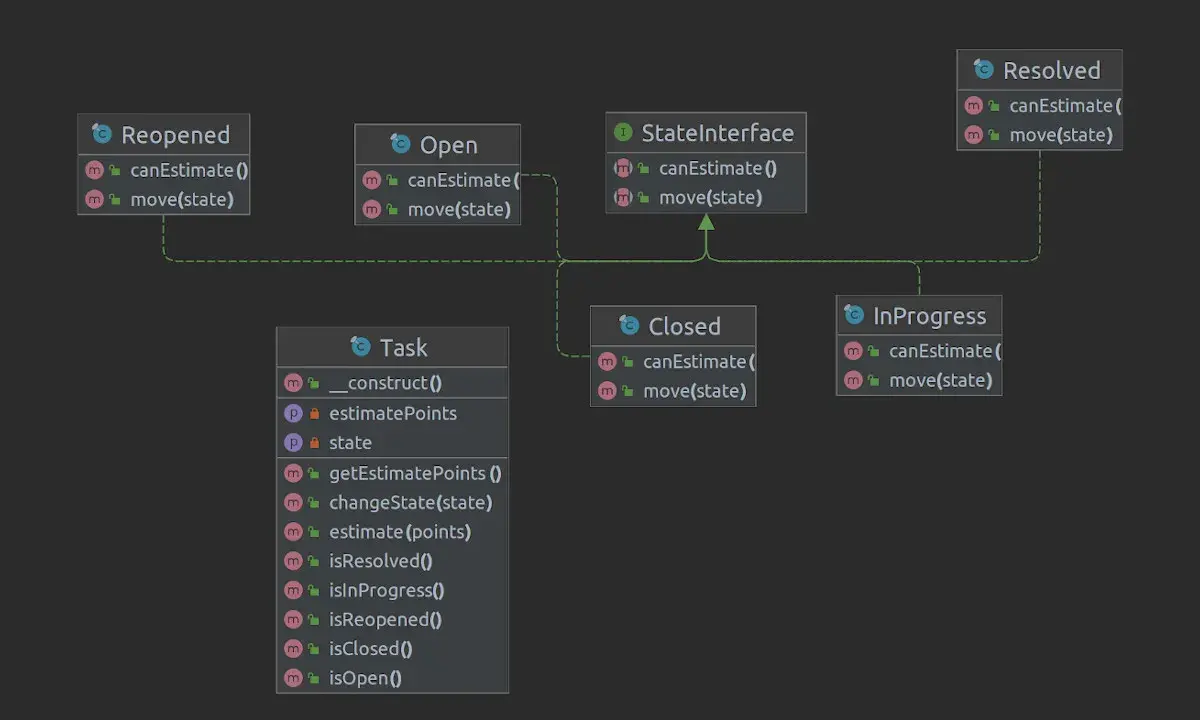
Jak go zapisać w kodzie bez chaosu
W implementacji zwykle wybieram jedno z trzech podejść: klasy stanów, tabela przejść albo prosty wariant oparty o enum i `switch`. Najbardziej elastyczny jest model obiektowy, bo każdy stan może mieć własne zachowanie. Najbardziej przewidywalna bywa tabela przejść, bo na jednym ekranie widzisz całą logikę. Najszybszy do napisania jest `switch`, ale tylko do momentu, w którym liczba reguł nie zacznie rosnąć.
| Podejście | Plusy | Minusy | Kiedy wybieram |
|---|---|---|---|
| Klasy stanów | Dobra enkapsulacja, czytelne zachowanie per stan | Więcej plików i klas | gdy logika w stanach różni się mocno |
| Tabela przejść | Widać cały przepływ w jednym miejscu | Akcje mogą się rozproszyć poza tabelą | gdy ważna jest przejrzystość i kontrola przejść |
| `switch` / `if` | Najprostszy start, mało narzutu | Szybko robi się nieczytelny | gdy stanów jest mało i raczej nie przybędzie |
W webowych projektach często dobrze działa prosty, jawny model przejść zapisany w strukturze danych. Na przykład zamiast rozrzucać warunki po kontrolerach i serwisach, trzymasz mapę dozwolonych przejść oraz funkcję, która sprawdza, czy dane zdarzenie jest legalne. To rozwiązanie jest szczególnie wygodne tam, gdzie logika biznesowa zmienia się rzadziej niż interfejs użytkownika.
const transitions = {
draft: { publish: "published", archive: "archived" },
published: { archive: "archived", restore: "draft" },
archived: { restore: "draft" }
};
function transition(state, event) {
const next = transitions[state]?.[event];
if (!next) {
throw new Error(`Nielegalne przejście: ${state} -> ${event}`);
}
return next;
}Taki zapis dobrze pokazuje sens wzorca: nie zgadujesz, co wolno, tylko sprawdzasz to wprost. W większym systemie dokładnie ten sam pomysł można rozwinąć o klasy, interfejsy, akcje wejścia i wyjścia oraz testy integracyjne. Im bardziej skomplikowana domena, tym bardziej opłaca się robić to jawnie.
To prowadzi do kolejnego pytania: gdzie w praktyce taki model najczęściej się przydaje, zwłaszcza w aplikacjach webowych, które rzadko są jednowątkowe i proste.Gdzie w aplikacjach webowych widać go najlepiej
W projektach webowych ten wzorzec pojawia się częściej, niż się wydaje. Różnica polega na tym, że czasem jest nazwany wprost, a czasem ukrywa się pod nazwą workflow, lifecycle albo status. Ja rozpoznaję go po tym, że obiekt ma wyraźny cykl życia i nie każda akcja jest dostępna w każdym momencie.
- Rejestracja i weryfikacja konta - konto może być nowe, zweryfikowane, zablokowane albo usunięte. Każdy krok ma inne reguły.
- Checkout i płatność - koszyk, rezerwacja, płatność oczekująca, opłacona, anulowana. Tu nielegalne przejścia są szczególnie kosztowne.
- Publikacja treści - szkic, w recenzji, opublikowane, zarchiwizowane. To klasyczny proces, w którym stan steruje uprawnieniami.
- Upload plików - przesyłanie, przetwarzanie, gotowe, błąd. Dobrze widać tu znaczenie zdarzeń asynchronicznych.
- Integracje i webhooks - system musi pamiętać, czy czeka na odpowiedź, czy już ją dostał, czy trzeba ponowić próbę.
W takich przypadkach wzorzec nie jest akademicką ozdobą, tylko sposobem na ograniczenie przypadkowych ścieżek. W UI pomaga też użytkownikowi, bo łatwiej pokazać, jakie akcje są dostępne teraz, a jakie dopiero później. To redukuje liczbę błędów po stronie produktu, nie tylko w kodzie.
Jeśli jednak proces zaczyna obejmować wiele systemów, wiele godzin lub dni oczekiwania i złożone retry, trzeba uważać. Wtedy sama maszyna stanów może być za mała i trzeba dołożyć warstwę orkiestracji. To ważna granica, bo właśnie na niej wiele projektów traci czytelność.Najczęstsze błędy, które psują cały efekt
Najgorszy błąd to nie sam wzorzec, tylko jego nadmierne rozbudowanie. Widziałem projekty, w których każdy drobiazg dostawał własny stan, a potem zespół walczył już nie z logiką biznesową, tylko z własnym modelem. Wtedy zamiast uproszczenia dostajesz formalnie poprawną, ale ciężką do utrzymania strukturę.
- Za dużo stanów - jeśli stanów jest zbyt wiele, model przestaje pomagać i zaczyna udawać precyzję.
- Ukryte przejścia - część logiki w serwisie, część w kontrolerze, część w klasie stanu. To przepis na błąd.
- Brak jednego źródła prawdy - jeśli nikt nie wie, gdzie naprawdę leży aktualny stan, testowanie staje się loterią.
- Mieszanie UI z domeną - interfejs powinien odczytywać stan, a nie go wymyślać.
- Ignorowanie nielegalnych przejść - system powinien je blokować jawnie, a nie „jakoś sobie radzić”.
- Zbyt wczesna abstrakcja - gdy problem jeszcze nie dojrzał, lepiej zacząć prościej i dopiero potem wydzielać stany.
Jeśli miałbym wskazać jedną rzecz do pilnowania, byłaby to spójność. Stan, przejście i akcja muszą być opisane w jednym logicznym modelu, inaczej wzorzec traci sens. Gdy ta spójność zostaje zachowana, zyskujesz system, który da się czytać, testować i rozwijać bez zgadywania.
Co zostaje po wdrożeniu, jeśli zrobisz to dobrze
Dobrze zaprojektowana maszyna stanów nie robi z kodu magii. Robi coś znacznie bardziej praktycznego: porządkuje decyzje, które wcześniej były rozrzucone po wielu miejscach. Dzięki temu łatwiej przewidzieć zachowanie systemu, szybciej napisać testy i bezpieczniej dodać nowy stan albo nowe przejście.
Jeśli miałbym zostawić jedną regułę na koniec, byłaby prosta: najpierw model domeny, potem implementacja. Gdy zaczynasz od dobrze nazwanych stanów i zdarzeń, wzorzec staje się naturalnym narzędziem architektonicznym. Gdy zaczynasz od kodu, bardzo łatwo zbudować coś, co wygląda elegancko, ale nie pomaga zespołowi pracować szybciej.
W praktyce ten wzorzec najlepiej działa tam, gdzie logika ma cykl życia, a nie tylko pojedynczą decyzję. Właśnie dlatego tak dobrze pasuje do aplikacji webowych, procesów biznesowych i części backendu, które muszą być przewidywalne. Jeśli potraktujesz go jako sposób na opisanie zmian, a nie jako modny termin, dostaniesz rozwiązanie, które naprawdę upraszcza architekturę.