Pętla for w C# to jedno z tych narzędzi, które szybko wydaje się banalne, a potem zaczyna decydować o czytelności całego fragmentu kodu. Ja zwykle traktuję ją jako najlepszy wybór tam, gdzie znam liczbę powtórzeń, pracuję na indeksach albo chcę mieć pełną kontrolę nad przebiegiem iteracji. W tym artykule pokazuję, jak działa składnia, kiedy lepiej wybrać inną pętlę, jakie błędy pojawiają się najczęściej i jak pisać kod, który łatwo utrzymać.
Najważniejsze rzeczy o pętli for w C#
- `for` sprawdza się najlepiej wtedy, gdy liczba iteracji jest znana albo łatwa do wyliczenia.
- Składnia ma trzy części: inicjalizację, warunek i krok iteracji.
- Do pracy na tablicach i indeksach `for` bywa wygodniejszy niż `foreach`.
-
whilelepiej pasuje do sytuacji, w których nie wiesz z góry, ile razy wykona się blok kodu. - Najczęstsze problemy to błąd granicy zakresu, brak aktualizacji licznika i modyfikowanie kolekcji w trakcie przejścia.
- W kodzie produkcyjnym ważniejsza od „sprytu” jest przewidywalność i czytelność.
Jak działa pętla for w C#
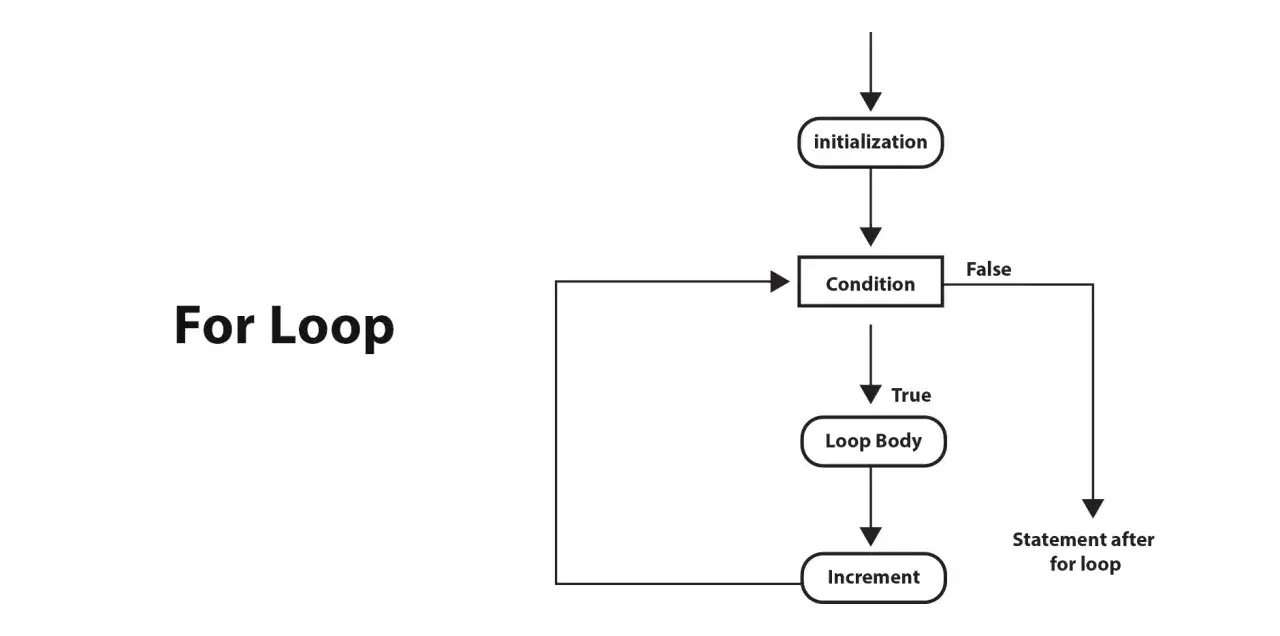
W praktyce pętla for składa się z trzech elementów: inicjalizacji, warunku i kroku iteracji. Najpierw ustawiasz licznik, potem sprawdzasz, czy pętla ma się wykonać, a na końcu po każdej iteracji aktualizujesz zmienną sterującą. To właśnie ten układ sprawia, że for jest tak wygodny przy prostych sekwencjach, licznikach i tablicach.
for (int i = 0; i < 5; i++)
{
Console.WriteLine(i);
}W tym przykładzie i = 0 to inicjalizacja, i < 5 to warunek zatrzymania, a i++ to krok wykonywany po każdej rundzie. Blok kodu w środku wykona się pięć razy: dla wartości od 0 do 4. Ja często przypominam sobie prostą zasadę: jeśli warunek nie ma się sam zmieniać, pętla najpewniej utknie.
Warto też pamiętać, że warunek jest sprawdzany przed każdą iteracją. To oznacza, że jeśli od razu jest fałszywy, blok wewnątrz pętli w ogóle się nie uruchomi. Ta cecha odróżnia for od niektórych innych konstrukcji i w praktyce daje dużą przewidywalność. Następny krok to wybór właściwej pętli do konkretnego zadania, bo nie każda iteracja powinna być robiona w ten sam sposób.
Kiedy for sprawdza się lepiej niż while i foreach
Ja patrzę na ten wybór bardzo pragmatycznie: jeśli chcesz kontrolować indeks, licznik lub zakres, for jest naturalnym kandydatem. Jeśli interesują cię same elementy kolekcji, bez indeksu, zwykle wygodniejszy będzie foreach. Gdy liczba powtórzeń zależy od warunku zewnętrznego, danych wejściowych albo zdarzenia, sensowniejszy bywa while.
| Konstrukcja | Kiedy użyć | Plusy | Ograniczenia |
|---|---|---|---|
for |
Gdy znasz zakres, licznik albo potrzebujesz indeksu | Pełna kontrola nad iteracją, łatwa praca z pozycjami | Łatwo o błąd granicy zakresu |
foreach |
Gdy chcesz przejść po elementach kolekcji | Czytelny, mniej podatny na błędy | Brak bezpośredniego sterowania indeksem |
while |
Gdy liczba iteracji zależy od warunku, którego nie liczysz z góry | Dobre do czekania na dane, próbkowania, logiki sterowanej stanem | Mniej „samowyjaśniający” przy prostych licznikach |
Jeśli pracujesz na tablicach, for daje coś, czego foreach nie daje od ręki: dostęp do indeksu. To ważne przy numerowaniu elementów, porównywaniu sąsiednich pozycji, odczycie konkretnego fragmentu lub odwracaniu kolejności. Z kolei while ma sens tam, gdzie licznik nie jest najważniejszy, tylko sam stan procesu. Taka selekcja pętli oszczędza później wiele poprawek, więc następny krok to konkretne przykłady, które pokazują to w kodzie.
Przykłady, które naprawdę się przydają
Sumowanie zakresu liczb
int suma = 0;
for (int i = 1; i <= 100; i++)
{
suma += i;
}
Console.WriteLine(suma);To klasyczny wzorzec akumulatora: każda iteracja dodaje swoją wartość do wyniku. Taki układ przydaje się nie tylko przy liczbach, ale też przy zliczaniu zdarzeń, budowaniu statystyk i prostych obliczeniach raportowych. Dla mnie to jeden z najlepszych pierwszych ćwiczeń, bo szybko pokazuje, jak działa zmienna narastająca.
Przejście po tablicy z indeksem
string[] produkty = { "Mleko", "Chleb", "Kawa" };
for (int i = 0; i < produkty.Length; i++)
{
Console.WriteLine($"{i}: {produkty[i]}");
}Tu widać największą siłę pętli for: masz jednocześnie element i jego pozycję. To praktyczne przy listach zamówień, indeksowaniu wyników wyszukiwania, generowaniu numeracji albo porównywaniu sąsiednich elementów. W C# pamiętaj o jednym szczególe: tablice są indeksowane od zera, więc ostatni poprawny indeks to Length - 1.
Odliczanie wstecz
for (int i = 10; i >= 0; i--)
{
Console.WriteLine(i);
}Odwrócony kierunek pętli jest bardzo użyteczny przy usuwaniu elementów, przechodzeniu od najnowszych danych do najstarszych albo przetwarzaniu listy od końca. Ja traktuję ten wariant jako dobry test zrozumienia pętli: jeśli umiesz wygodnie pisać zarówno „do przodu”, jak i „wstecz”, masz nad nią realną kontrolę.
Przeczytaj również: Python: zmienne globalne - kiedy używać, kiedy unikać?
Krok większy niż jeden
for (int i = 0; i <= 20; i += 2)
{
Console.WriteLine(i);
}Ten wariant jest sensowny, gdy logika naprawdę opiera się na skoku, a nie na każdym kolejnym elemencie. Może to być co drugi rekord, próbkowanie danych albo iteracja po indeksach parzystych. Nie warto jednak używać takiego kroku tylko po to, żeby kod wyglądał „sprytniej” niż zwykła pętla.
Najczęstsze błędy, które psują pętlę
Najwięcej problemów z for nie wynika z samej składni, tylko z detali. To właśnie drobne pomyłki powodują wyjątki, nieskończone pętle albo wyniki, które są „prawie dobre”, ale jednak błędne. W praktyce warto zwrócić uwagę na kilka powtarzalnych pułapek.
-
Błąd granicy zakresu - przy tablicach i listach zwykle chcesz używać
<, a nie<=. Zbyt szeroki warunek kończy się wyjściem poza zakres. - Brak aktualizacji licznika - jeśli krok iteracji nie zmienia wartości, pętla może działać bez końca.
- Modyfikowanie kolekcji w trakcie przejścia - usuwanie lub dodawanie elementów podczas iteracji łatwo psuje logikę, zwłaszcza gdy pracujesz na indeksach.
- Zbyt skomplikowany nagłówek - jeśli w warunku zaczynasz robić obliczenia albo wywoływać metody z efektami ubocznymi, kod staje się trudniejszy do utrzymania.
- Mieszanie logiki i licznika - im bardziej licznik robi za wszystko naraz, tym trudniej później zrozumieć, co właściwie ma kontrolować pętlę.
// Błędny wzorzec przy tablicy:
for (int i = 0; i <= tablica.Length; i++)
{
Console.WriteLine(tablica[i]);
}W tym przykładzie ostatnia iteracja próbuje wejść poza zakres, bo ostatni poprawny indeks nie jest równy Length, tylko Length - 1. To drobiazg, ale właśnie takie drobiazgi najczęściej kosztują czas podczas debugowania. Następny temat to sytuacje, w których jedna pętla nie wystarcza i trzeba sięgnąć po dwie.
Pętle zagnieżdżone i praca na tablicach dwuwymiarowych
Pętle zagnieżdżone pojawiają się wtedy, gdy trzeba przejść po strukturze w strukturze, na przykład po tabeli, macierzy, siatce danych albo układzie wierszy i kolumn. To naturalne rozwiązanie, ale ma swoją cenę: liczba operacji rośnie bardzo szybko, więc przy większych zbiorach danych trzeba zachować ostrożność. Ja lubię o tym myśleć tak: zagnieżdżona pętla jest dobra, gdy model danych rzeczywiście jest wielowymiarowy, a nie wtedy, gdy chcemy na siłę uprościć zbyt duży problem.
int[,] plansza =
{
{ 1, 2, 3 },
{ 4, 5, 6 }
};
for (int wiersz = 0; wiersz < plansza.GetLength(0); wiersz++)
{
for (int kolumna = 0; kolumna < plansza.GetLength(1); kolumna++)
{
Console.Write($"{plansza[wiersz, kolumna]} ");
}
Console.WriteLine();
}GetLength(0) zwraca liczbę wierszy, a GetLength(1) liczbę kolumn. Taki układ przydaje się przy tabelach, kalendarzach, planszach gier, siatkach cenowych i prostych analizach danych. Jeśli jednak liczba elementów rośnie, warto myśleć o kosztach obliczeniowych, bo dwa zagnieżdżone przebiegi bardzo szybko robią się drogie. Z tego powodu kolejny krok to nie tylko poprawność, ale też styl pisania takiej pętli.
Jak pisać kod, który zostaje czytelny po kilku miesiącach
Najbardziej lubię kod, który nie wymaga zgadywania intencji autora. W przypadku for oznacza to kilka prostych zasad: licznik ma mieć sensowną nazwę, warunek ma być prosty, a ciało pętli nie powinno robić zbyt wielu rzeczy naraz. Jeśli pętla zaczyna przypominać mały program w programie, zwykle warto wyciągnąć część logiki do osobnej metody.
- Używaj nazw bardziej opisowych niż samo
i, jeśli masz kilka poziomów pętli:wiersz,kolumna,index,day. - Trzymaj warunek możliwie blisko prostego porównania, bez ukrytych efektów ubocznych.
- Nie przesadzaj z mikrooptymalizacją, jeśli kod nie jest w gorącym miejscu wykonania.
- Gdy potrzebujesz tylko przejść po elementach, bez indeksu, często lepiej brzmi
foreach. - Jeśli pętla ma więcej niż kilka prostych linii, rozważ wydzielenie pomocniczej metody.
W praktyce wydajność rzadko jest powodem, dla którego wybieram for zamiast innych konstrukcji. Częściej chodzi o przejrzystość i kontrolę nad indeksami. Tam, gdzie naprawdę ma znaczenie czas wykonania, i tak warto najpierw profilować kod, a dopiero potem zmieniać konstrukcję iteracji. To prowadzi do ostatniej części: jak ćwiczyć tę pętlę, żeby została w głowie na dłużej.
Co warto przećwiczyć, żeby for weszło w nawyk
Najlepsza droga do opanowania tej konstrukcji jest bardzo praktyczna. Zamiast czytać kolejne definicje, zrób kilka małych ćwiczeń i sprawdź, czy naprawdę rozumiesz trzy rzeczy: kiedy pętla startuje, kiedy się kończy i jak zmienia się licznik.
- wypisz liczby od 1 do 10
- policz sumę liczb z wybranego zakresu
- przejdź po tablicy od początku do końca
- przejdź po tablicy od końca do początku
- wypisz co drugi element
- przejdź po macierzy 2D i wypisz wartości w układzie wierszy
Gdy piszę własną pętlę, zawsze sprawdzam dwie rzeczy: czy warunek na pewno zmienia się w czasie i czy ostatni indeks nie wyjdzie poza zakres. Taki nawyk usuwa większość błędów jeszcze zanim zaczniesz debugowanie. Jeśli opanujesz ten rytm pracy, pętla for stanie się czymś więcej niż składnią, po prostu wygodnym sposobem myślenia o iteracji.