W bazach danych self join SQL przydaje się wtedy, gdy jedna tabela opisuje dwie role tego samego obiektu: pracownika i jego przełożonego, kategorię i nadrzędny węzeł albo dwa rekordy, które trzeba porównać ze sobą. To prosta technika w założeniu, ale bez dobrych aliasów i sensownego warunku łączenia łatwo dostać duplikaty, chaos w zapytaniu albo wynik, który wygląda poprawnie tylko na pierwszy rzut oka. Poniżej pokazuję, jak to działa w praktyce, kiedy ma sens i kiedy lepiej sięgnąć po inne narzędzie.
Najważniejsze zasady łączenia tabeli z samą sobą
- To nie jest osobny typ tabeli, tylko zwykły join wykonany na dwóch instancjach tej samej tabeli.
- Alias jest tu w praktyce obowiązkowy, bo rozróżnia role rekordów i usuwa niejednoznaczność.
- Najczęściej używa się go w hierarchiach, relacjach parent-child i porównywaniu rekordów w obrębie jednej tabeli.
- Jeśli porównujesz pary, warunek
<często lepiej niż<>usuwa lustrzane duplikaty. - Do pełnych drzew lepszy bywa rekurencyjny CTE, a do prostych filtrów czasem wystarcza podzapytanie.
- Wydajność zwykle poprawia indeks na kolumnie łączenia i filtr ograniczający dane jak najwcześniej.
Na czym polega łączenie tabeli z samą sobą
Ja patrzę na ten mechanizm tak: jedna tabela, dwie role, jeden warunek łączenia. Najpierw nadajesz rekordom różne aliasy, potem porównujesz wskazane kolumny tak, jakby pochodziły z dwóch osobnych źródeł. Dzięki temu możesz pokazać zależności, które w modelu relacyjnym siedzą wewnątrz jednej tabeli, bez dokładania sztucznych kopii danych.
Najczęściej chodzi o relację nadrzędny-podrzędny albo o porównanie rekordów między sobą. Jeśli tabela opisuje strukturę firmy, kategorii albo komentarzy, taki join pozwala odczytać tę strukturę wprost z danych. Jeśli tabela zawiera równorzędne wpisy, ta sama technika pomaga znaleźć pary, duplikaty lub rekordy z tej samej grupy. Żeby to działało bez chaosu, trzeba dobrze opanować aliasy, bo bez nich samo zapytanie szybko robi się nieczytelne.
Dlaczego aliasy są tu konieczne
Tu nie ma miejsca na skróty myślowe. Po nadaniu aliasu silnik SQL traktuje go jak nową nazwę tej instancji tabeli, więc w dalszej części zapytania odwołujesz się już do aliasu, a nie do oryginalnej nazwy. To rozwiązuje problem niejednoznaczności, który pojawia się natychmiast, gdy ta sama tabela występuje dwa razy.
SELECT
e.name AS employee_name,
m.name AS manager_name
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id;W takich zapytaniach wolę aliasy opisujące rolę danych: e i m, child i parent, a1 i a2. Krótkie nazwy są dobre, ale tylko wtedy, gdy nadal widać, kto jest kim. Jeśli po kilku liniach sam zaczynam się gubić, to znak, że aliasy są zbyt skrótowe. Gdy mechanika jest już jasna, najwięcej daje zobaczenie gotowych wzorców na realnych tabelach.
Przykłady, które najczęściej spotyka się w bazach danych
Najłatwiej zrozumieć ten temat na dwóch sytuacjach, które naprawdę wracają w projektach: hierarchii oraz porównywaniu rekordów z tej samej tabeli. To są dwa miejsca, w których self join robi konkretną robotę, a nie tylko wygląda dobrze w przykładzie z podręcznika.
Pracownik i przełożony
To klasyczny układ parent-child. Jeden rekord wskazuje inny rekord w tej samej tabeli, zwykle przez manager_id, parent_id albo podobną kolumnę. Używam LEFT JOIN, gdy chcę zachować też rekordy bez rodzica, na przykład dyrektora generalnego albo kategorię najwyższego poziomu.
SELECT
e.id,
e.name AS employee_name,
m.name AS manager_name
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id;W tym wariancie widać od razu dwie rzeczy: kto jest pracownikiem i kto jest przełożonym. Gdy ktoś nie ma menedżera, kolumna z nazwą przełożonego zostaje pusta, ale sam rekord nadal trafia do wyniku. W hierarchiach to zwykle ważniejsze niż idealnie „czysty” wynik bez żadnych nulli.
Przeczytaj również: Rekurencja w programowaniu - Czy na pewno ją rozumiesz?
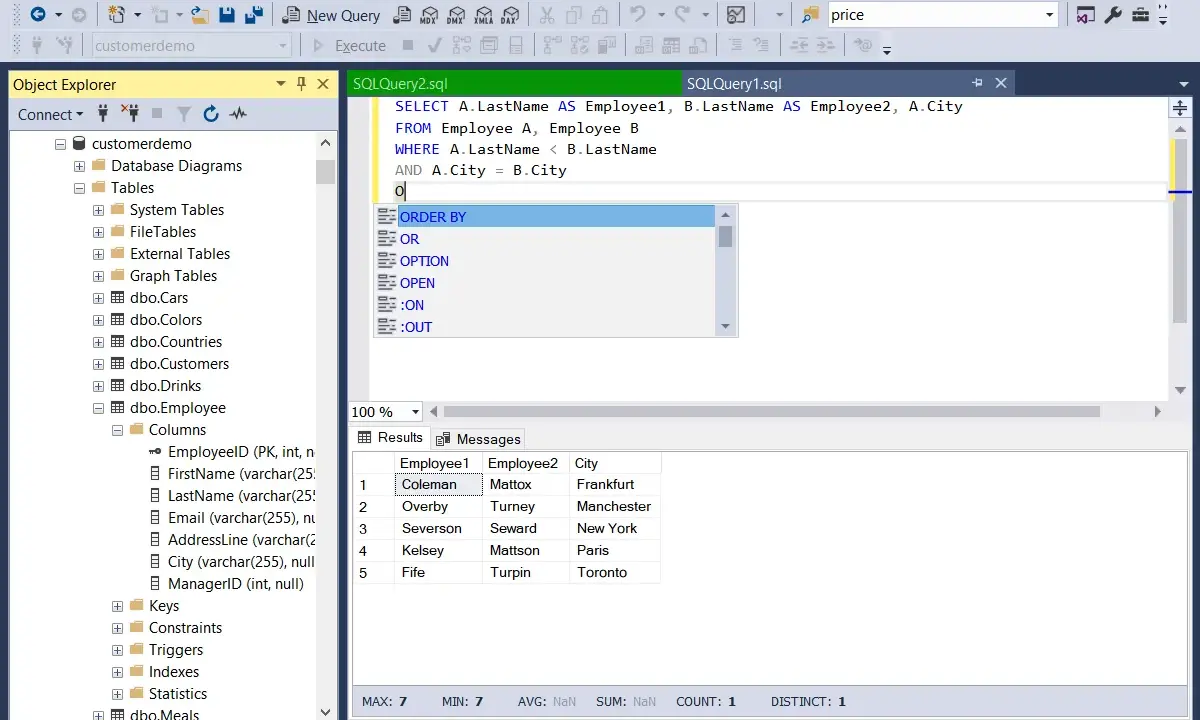
Rekordy z tej samej grupy
Drugi częsty przypadek to wyszukiwanie par rekordów należących do tej samej grupy, na przykład autorów z tego samego miasta, użytkowników z tej samej organizacji albo produktów z tej samej kategorii. Tu najłatwiej wpaść w problem podwójnych wyników: raz dostajesz A-B, a chwilę później B-A.
SELECT
a1.full_name,
a2.full_name,
a1.city
FROM authors a1
JOIN authors a2
ON a1.city = a2.city
AND a1.id < a2.id;Warunek a1.id < a2.id robi dwie rzeczy naraz: usuwa parę rekordu z samym sobą i kasuje lustrzane duplikaty. Zamiast dwóch wierszy dostajesz jeden wynik, który da się sensownie policzyć, wyświetlić albo wykorzystać w dalszym przetwarzaniu. Ten sam wzorzec działa przy tabelach categories, comments czy employees, jeśli trzeba porównać elementy wewnątrz jednej grupy. Kiedy taki wzorzec zaczyna zwracać dziwne powtórki, zwykle problem nie leży w samej technice, tylko w warunku łączenia.
Najczęstsze błędy, które psują wynik
- Brak warunku wykluczającego ten sam rekord - wtedy rekord łączy się z samym sobą, a wynik puchnie od mało przydatnych wierszy.
-
Użycie złego typu złączenia -
INNER JOINbywa za ostry dla hierarchii, bo ucina rekordy bez rodzica. - Zbyt ogólny warunek - łączenie po samej nazwie miasta, statusie albo roczniku szybko daje fałszywe pary.
- Za dużo kolumn w SELECT - gdy pokazujesz wszystko, trudniej zauważyć, czy logika porównania naprawdę działa.
- Brak indeksu na kolumnie łączenia - na małych tabelach tego nie widać, na większych różnica potrafi być bardzo wyraźna.
Ja najpierw doprowadzam zapytanie do poprawnych wyników, a dopiero potem sprawdzam, czy plan wykonania nie pokazuje zbędnych skanów. To oszczędza czas, zwłaszcza kiedy baza rośnie. Ale nie każda sytuacja, w której dwie części zapytania odnoszą się do tej samej tabeli, naprawdę wymaga tego samego rozwiązania.
Kiedy lepiej wybrać CTE, podzapytanie albo funkcję okna
Nie każda sytuacja, w której dwie części zapytania odnoszą się do tej samej tabeli, wymaga self joinu. Czasem czytelniejsze i bardziej elastyczne będzie rozwiązanie oparte na CTE, podzapytaniu albo funkcji okna. Wybór robi sporą różnicę, bo chodzi nie tylko o wynik, ale też o to, czy ktoś za pół roku zrozumie intencję zapytania.
| Rozwiązanie | Kiedy ma sens | Dlaczego je wybieram | Na co uważać |
|---|---|---|---|
| Self join | Relacje między dwiema rolami tej samej tabeli | Jest bezpośredni i czytelny | Łatwo o duplikaty i bałagan w aliasach |
| Rekurencyjny CTE | Drzewa i wiele poziomów zależności | Obsługuje pełną hierarchię | Więcej składni i większa złożoność |
| Podzapytanie | Proste filtrowanie tej samej tabeli | Często bywa krótsze | Trudniej nim wygodnie zwracać pary rekordów |
| Funkcja okna | Analiza kolejności, rankingu i sąsiednich wierszy | Bardzo dobra do obliczeń analitycznych | Nie zastępuje relacji parent-child |
Jeśli mam porównać te opcje jednym zdaniem, to self join wygrywa wtedy, gdy potrzebuję relacji „rekord do rekordu” w obrębie jednej tabeli, a nie całego drzewa albo samego filtrowania. Gdy problem jest głębszy niż jeden poziom zależności, rekurencyjny CTE zwykle robi lepszą robotę. Z kolei przy analizie kolejności rekordów coraz częściej wygodniej wejść w funkcje okna niż próbować wszystko sklejać joinem.
Jak pisać takie zapytania, żeby dało się je utrzymać
W praktyce największą różnicę robi nie sam join, tylko dyscyplina w pisaniu zapytań. Ja trzymam się kilku prostych zasad: aliasy mają opisywać role, warunek łączenia ma być możliwie precyzyjny, a wynik ma zawierać tylko te kolumny, które coś wyjaśniają. To banalne, ale bardzo skuteczne.
- Nazywaj aliasy według roli danych, a nie losowo.
- Porównuj tylko kolumny, które naprawdę opisują relację między rekordami.
- Jeśli chcesz jedną parę zamiast dwóch symetrycznych wierszy, użyj warunku
<. - Filtruj dane możliwie wcześnie, zanim join zacznie mnożyć wiersze.
- Sprawdzaj plan wykonania, jeśli tabela ma większy wolumen.
- Dodaj indeks na kolumnie, po której łączysz rekordy, jeśli ten wzorzec pojawia się często.
Jeżeli miałbym zostawić jedną praktyczną wskazówkę, byłaby taka: łączenie tabeli z samą sobą jest świetne do lokalnych zależności i porównań, ale nie powinno być domyślnym narzędziem do każdego problemu z tą samą tabelą. Gdy zapytanie zaczyna wyglądać jak mała łamigłówka, zwykle warto wrócić do pytania, czy lepiej wyjdzie self join, CTE czy po prostu prostszy filtr.