
Rekurencja to jeden z tych tematów, które na początku wyglądają groźnie, a po rozłożeniu na części okazują się bardzo logiczne. W programowaniu chodzi o sytuację, w której funkcja rozwiązuje problem przez wywołanie samej siebie, ale zawsze dla prostszego przypadku i z wyraźnym warunkiem zakończenia. W tym tekście pokazuję, jak to działa, kiedy ma sens, gdzie początkujący najczęściej się mylą i dlaczego w kodzie webowym ten mechanizm bywa naprawdę użyteczny.
Najważniejsze rzeczy o rekurencji w kilku punktach
- Funkcja wywołuje samą siebie, ale tylko wtedy, gdy z każdą rundą problem staje się prostszy.
- Dwa elementy są obowiązkowe: przypadek bazowy i krok rekurencyjny.
- Najlepiej sprawdza się przy strukturach drzewiastych, np. DOM, menu i komentarzach.
- Największe ryzyko to brak warunku końcowego i przepełnienie stosu.
- Do prostych iteracji pętla bywa czytelniejsza i bezpieczniejsza.
Na czym polega rekurencja w programowaniu
W dokumentacji MDN rekurencja jest opisywana bardzo prosto: funkcja wywołuje samą siebie, żeby poradzić sobie z problemem, który można rozbić na mniejsze podproblemy. To nie jest sztuczka składniowa, tylko sposób myślenia o zadaniu. Ja patrzę na rekurencję jak na umowę: jeśli potrafię rozwiązać mniejszą wersję problemu, to złożę z tego rozwiązanie większego.
Przypadek bazowy
To punkt stopu. Bez niego funkcja będzie wywoływać się bez końca albo do momentu, w którym środowisko przerwie działanie. W praktyce przypadek bazowy powinien być prosty, jednoznaczny i łatwy do sprawdzenia.
Przeczytaj również: Gumowa Kaczka - Jak debugować kod krok po kroku?
Krok rekurencyjny
To część, w której funkcja przekazuje do kolejnego wywołania mniejszy, prostszy lub bardziej zawężony problem. Dobre wywołanie rekurencyjne nie kręci się w miejscu: z każdą iteracją ma być bliżej rozwiązania. Jeśli ten warunek nie jest spełniony, kod wygląda elegancko tylko na pierwszy rzut oka.
Kiedy te dwa elementy są ustawione dobrze, można przejść do tego, co dzieje się przy wykonaniu programu, bo tam rekurencja zaczyna być naprawdę zrozumiała.
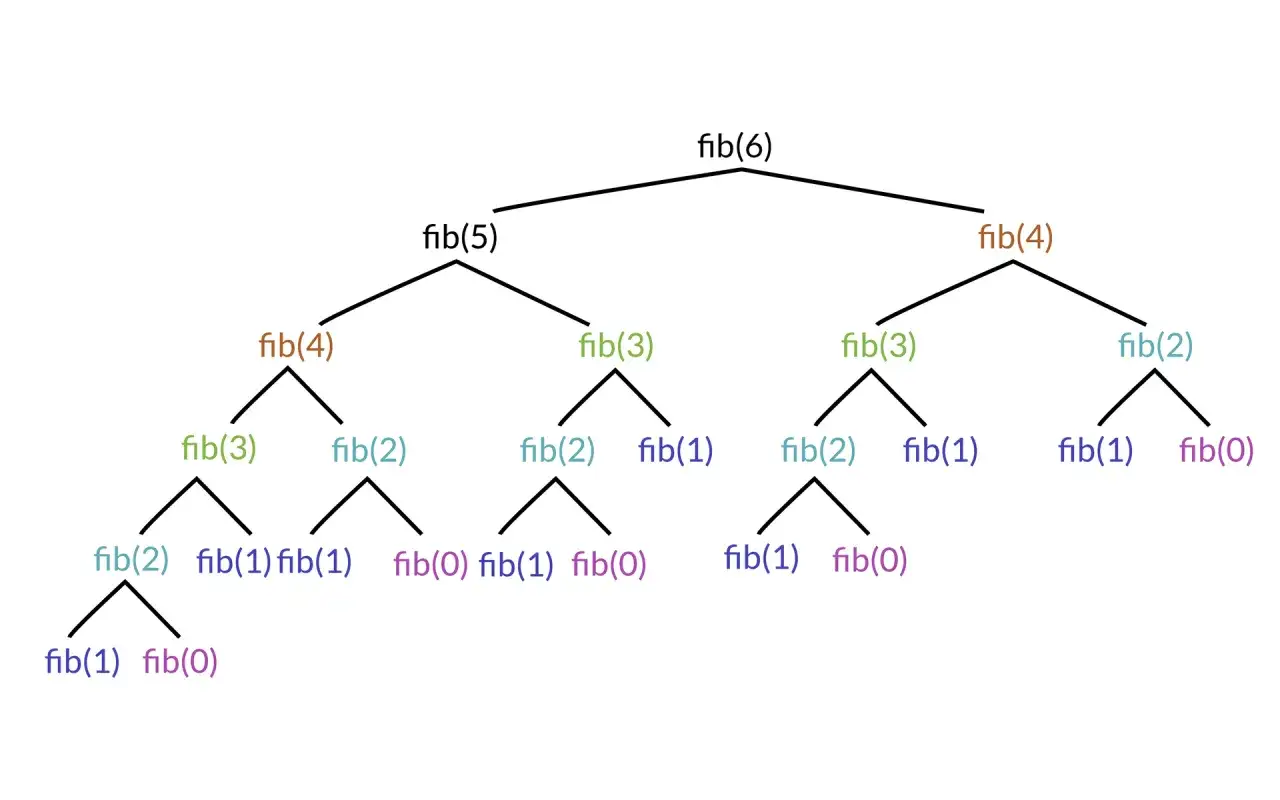
Jak wywołanie rekurencyjne zachowuje się krok po kroku
Najłatwiej wytłumaczyć to na silni. Jeśli liczę silnię 4, funkcja najpierw prosi o silnię 3, potem 2, potem 1, a na końcu dochodzi do przypadku bazowego. Dopiero potem wyniki wracają w górę i składane są w jedną wartość.
function silnia(n) {
if (n === 0) return 1;
return n * silnia(n - 1);
}-
silnia(4)prosi osilnia(3). -
silnia(3)prosi osilnia(2). -
silnia(2)prosi osilnia(1). -
silnia(1)dochodzi do warunku końcowego przezsilnia(0). - Wynik wraca w górę: 1, 2, 6, 24.
Tu dobrze widać dwie rzeczy. Po pierwsze, każde wywołanie pracuje na prostszym wejściu. Po drugie, program odkłada kolejne wywołania na stosu wywołań, czyli wewnętrznej strukturze pamięci, która pamięta, kto kogo wywołał. Gdy następuje powrót z funkcji, silnia 1 zwraca 1, silnia 2 zwraca 2, silnia 3 zwraca 6, a silnia 4 daje 24.
Właśnie dlatego rekurencja bywa tak czytelna przy problemach o naturalnej strukturze zagnieżdżonej. To prowadzi do pytania, gdzie naprawdę opłaca się ją pokazać na konkretnych przykładach.
Przykłady, które najlepiej pokazują sens rekurencji
Najbardziej klasyczny przykład to silnia. Jest prosty, dlatego często pojawia się na start, ale sam w sobie rzadko jest najlepszym powodem, by w produkcyjnym kodzie sięgać po rekurencję. Dobrze nadaje się do nauki, bo widać w nim wyraźnie przypadek bazowy i krok rekurencyjny.
Drugi przykład to dane o strukturze drzewa, czyli na przykład zagnieżdżone menu w serwisie, komentarze pod wpisem albo elementy DOM w przeglądarce. Jeśli każdy element może mieć własne dzieci, rekurencja zwykle pozwala przejść po takiej strukturze naturalniej niż długa seria zagnieżdżonych instrukcji if.
function przejdzDrzewo(node) {
console.log(node.name);
for (const child of node.children) {
przejdzDrzewo(child);
}
}Ten wzorzec jest ważny w web developmencie, bo drzewo DOM samo w sobie ma charakter zagnieżdżony. Jeśli umiesz przejść po strukturze komentarzy, menu albo komponentów, łatwiej zrozumiesz również kod frameworków, które operują na podobnym modelu danych.
Trzeci przykład to algorytmy „dziel i zwyciężaj”, w których problem rozbijasz na mniejsze części, rozwiązujesz je osobno, a potem składasz wynik. Tu rekurencja często jest najbardziej naturalnym zapisem pomysłu, nawet jeśli ostateczna implementacja nie zawsze musi wyglądać rekurencyjnie. Po takich przykładach sensowne jest już uczciwe porównanie z pętlą.
Rekurencja i pętla nie są tym samym narzędziem
Ja traktuję rekurencję jako dobre rozwiązanie dla problemów z wyraźnym podziałem na mniejsze wersje tego samego zadania, a pętlę jako domyślny wybór do prostych, liniowych przebiegów. To nie jest wojna technologii, tylko kwestia dopasowania narzędzia do kształtu problemu.
| Cecha | Rekurencja | Pętla |
|---|---|---|
| Sposób myślenia | Problem rozbijany na mniejsze podproblemy | Powtarzanie tej samej operacji dla kolejnych danych |
| Czytelność | Świetna przy drzewach, listach zagnieżdżonych i „dziel i zwyciężaj” | Lepsza przy prostych przebiegach i iteracji po tablicy |
| Zużycie pamięci | Wyższe, bo każde wywołanie trafia na stos | Zwykle niższe |
| Ryzyko błędu | Brak warunku końcowego, zbyt głębokie wywołania | Zły warunek pętli, nieskończona iteracja |
| Najlepsze zastosowanie | Struktury drzewiaste, przetwarzanie podproblemów | Liczniki, proste listy, operacje sekwencyjne |
W praktyce w JavaScript pętla bardzo często wygrywa prostotą i przewidywalnością, zwłaszcza gdy chodzi o zwykłe iterowanie po danych. Rekurencja zaczyna błyszczeć wtedy, gdy struktura problemu sama podpowiada taki zapis. Z tego właśnie powodu warto też znać jej ograniczenia, bo one decydują o tym, czy kod będzie elegancki, czy tylko efektowny.
Najczęstsze błędy i ograniczenia, o których trzeba pamiętać
Najprostszy błąd to brak przypadku bazowego. Wtedy funkcja nie ma gdzie się zatrzymać i kończy się to błędem typu „too much recursion” albo komunikatem o przekroczonym rozmiarze stosu. W JavaScript dokładny limit zależy od silnika i środowiska, więc nie ma jednego bezpiecznego progu, którego można się trzymać zawsze.
- Brak zmniejszania problemu - jeśli kolejne wywołanie dostaje ten sam albo prawie ten sam stan, funkcja kręci się w kółko.
- Zbyt głębokie zagnieżdżenie - nawet poprawna rekurencja może przestać działać, jeśli wejście jest zbyt duże.
- Nieczytelny przypadek bazowy - gdy warunek stopu jest ukryty w kilku warstwach logiki, debugowanie robi się niepotrzebnie trudne.
- Użycie rekurencji tam, gdzie wystarczy pętla - wtedy kod bywa cięższy do utrzymania bez realnego zysku.
To jest moment, w którym doświadczenie naprawdę pomaga. Dobra rekurencja nie ma wyglądać „mądrze” - ma działać jasno, kończyć się przewidywalnie i nie tworzyć problemów z pamięcią. Jeśli spełnia te warunki, można zacząć pisać własne rozwiązania tak, żeby były proste od pierwszej wersji.
Jak pisać prostą i bezpieczną rekurencję w praktyce
Gdy sam projektuję takie funkcje, zaczynam od trzech pytań: jaki jest najmniejszy możliwy przypadek, jak problem zmniejsza się po każdym wywołaniu i czy naprawdę potrzebuję rekurencji, a nie zwykłej pętli. Ten prosty test często oszczędza więcej czasu niż późniejsze poprawianie kodu.
- Zacznij od końca. Najpierw ustal warunek stopu, dopiero potem buduj krok rekurencyjny.
- Sprawdzaj małe wejścia. Test na 0, 1 albo pustą strukturę szybko pokazuje, czy kod ma sens.
- Patrz na głębokość danych. Jeśli wejście może rosnąć bez kontroli, pomyśl o iteracji albo własnym stosie.
Rekurencja nie jest trudna sama w sobie. Trudne bywa dopiero dopasowanie jej do problemu, który naprawdę na nią zasługuje. Gdy to się uda, kod staje się krótszy, bardziej naturalny i zwyczajnie łatwiejszy do zrozumienia dla kolejnej osoby, która po niego sięgnie.