
Dobra architektura aplikacji webowych decyduje o tym, czy produkt rośnie spokojnie, czy po kilku sprintach zamienia się w zlepek zależności, których nikt nie chce dotykać. W tym tekście rozkładam temat na praktyczne elementy: warstwy systemu, popularne wzorce, kryteria wyboru i błędy, które najczęściej podnoszą koszty utrzymania. Skupiam się na rozwiązaniach, które da się wykorzystać w realnym projekcie, a nie tylko narysować na tablicy.
Najważniejsze są granice odpowiedzialności, prosty rozwój i możliwość bezpiecznych zmian
- Warstwy pomagają oddzielić interfejs, logikę biznesową, dostęp do danych i integracje.
- Monolit modularny bywa lepszym startem niż mikroserwisy, bo mniej kosztuje operacyjnie.
- Mikroserwisy mają sens wtedy, gdy różne części systemu naprawdę da się rozwijać i skalować osobno.
- SSR i CSR nie wykluczają się wzajemnie; w wielu projektach najlepiej działa układ mieszany.
- Najdroższy błąd to wczesne skomplikowanie systemu bez realnej potrzeby biznesowej.
Z czego składa się dobrze poukładany system webowy
Na architekturę patrzę przede wszystkim jak na sposób rozdzielenia odpowiedzialności. Interfejs użytkownika zbiera intencje, warstwa aplikacyjna steruje przepływem, domena pilnuje reguł biznesowych, a warstwa danych zapisuje i odczytuje stan. Jeśli te części są wyraźnie oddzielone, łatwiej coś poprawić, przetestować albo podmienić bez rozkręcania całego projektu.
Microsoft Learn zwraca uwagę, że dobrze zorganizowane warstwy ułatwiają izolowanie zmian i testowanie, bo można podmieniać implementacje bez dotykania reszty systemu. To właśnie dlatego separacja nie jest ozdobą diagramu, tylko realnym narzędziem ograniczania kosztów.
Co wydzielam od początku
- Warstwę prezentacji - odpowiada za widoki, formularze, routing i interakcje użytkownika.
- Warstwę aplikacyjną - orkiestruje use case’y, czyli konkretne przypadki użycia, na przykład „złóż zamówienie” albo „zmień hasło”.
- Warstwę domenową - trzyma reguły biznesowe, które nie powinny zależeć od frameworka.
- Warstwę dostępu do danych - odpowiada za zapis, odczyt, migracje i sposób komunikacji z bazą.
- Integracje i zadania asynchroniczne - maile, webhooki, kolejki, raporty, synchronizacje z zewnętrznymi usługami.
- Obserwowalność - logi, metryki i ślady zdarzeń, bez których diagnoza problemów szybko robi się zgadywaniem.
W praktyce to nie front-end i back-end są najważniejszym podziałem, tylko granice odpowiedzialności wewnątrz systemu. Gdy te granice są jasne, łatwiej ocenić, który wzorzec naprawdę pasuje do projektu.
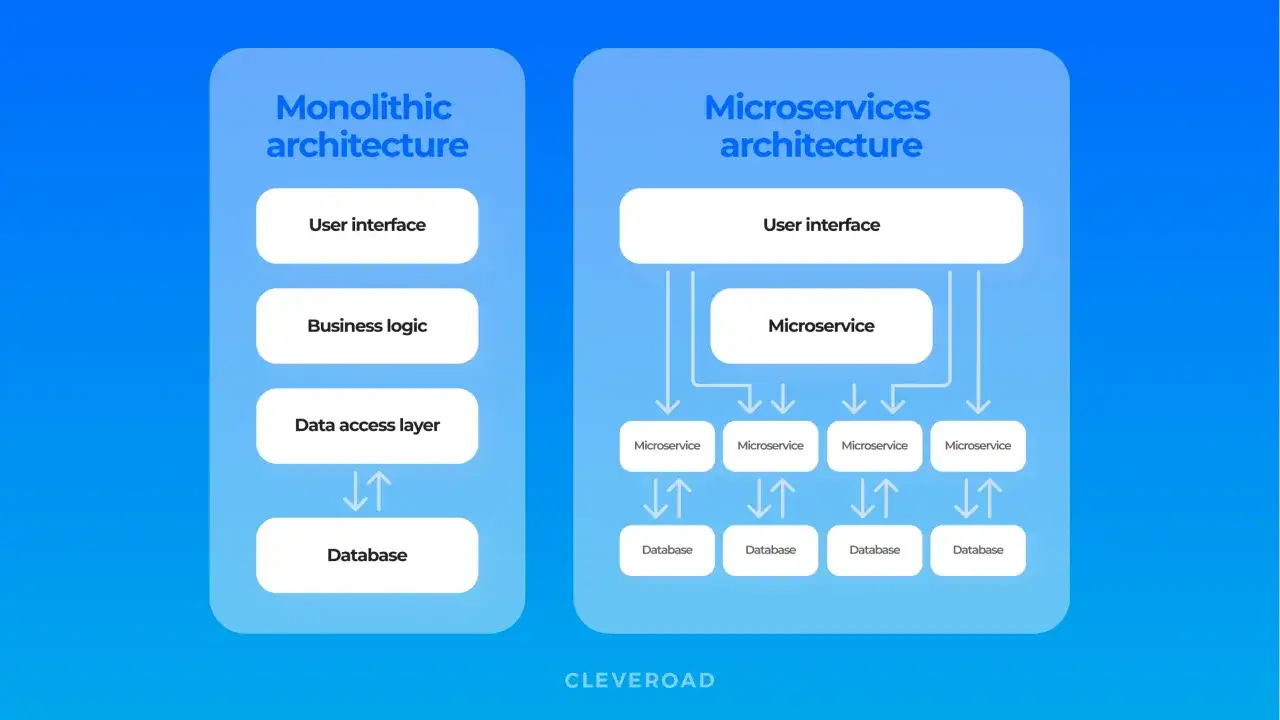
Najczęstsze wzorce i kiedy każdy z nich ma sens
Nie ma jednego modelu, który wygrywa wszędzie. Ja zwykle wybieram wzorzec po tym, jak bardzo zespół potrzebuje niezależności, jak często zmienia się logika biznesowa i ile kosztuje wdrożenie oraz utrzymanie. Właśnie tu najłatwiej przesadzić z ambicją albo przeciwnie - zamknąć się w zbyt sztywnej strukturze.
| Wzorzec | Kiedy ma sens | Mocne strony | Gdzie pojawia się koszt |
|---|---|---|---|
| Monolit warstwowy | Mały lub średni produkt, jeden zespół, szybki start | Prosty deployment, niski narzut operacyjny, łatwiejsze testy end-to-end | Z czasem rośnie ryzyko ciasnych zależności i trudniejszego refaktoringu |
| Monolit modularny | Projekt ma rosnąć, ale nie ma jeszcze potrzeby rozbijania go na usługi | Lepsze granice modułów, mniejsze ryzyko chaosu, nadal jeden deployment | Wymaga dyscypliny zespołu i konsekwencji w pilnowaniu granic |
| Mikroserwisy | Wiele niezależnych domen, kilka zespołów, osobne tempo zmian | Samodzielne wdrażanie, niezależne skalowanie, większa autonomia zespołów | Więcej DevOps, obserwowalności, kontraktów API i problemów sieciowych |
| Architektura zdarzeniowa | Dużo integracji, procesy asynchroniczne, kolejki, webhooki, powiadomienia | Dobra odporność na skoki ruchu, luźniejsze powiązania, łatwiejsze rozproszenie pracy | Trudniejsze debugowanie i większa potrzeba kontroli spójności danych |
AWS opisuje mikroserwisy jako niezależne komponenty komunikujące się przez lekkie API. To ważne, bo w praktyce mikroserwis nie jest po prostu „małym backendem”, tylko usługą z własną odpowiedzialnością, własnym cyklem wdrożenia i własnym kosztem operacyjnym. Jeśli tego kosztu nie zaakceptujesz, ten model szybko zacznie przeszkadzać.
Renderowanie strony to osobna decyzja
W warstwie front-endu często miesza się dwie rzeczy: SSR i CSR. SSR, czyli renderowanie po stronie serwera, oznacza generowanie HTML na serwerze i wysłanie go do przeglądarki. CSR robi odwrotnie - buduje interfejs w przeglądarce za pomocą JavaScriptu. MDN podkreśla, że oba podejścia mogą współistnieć w jednej aplikacji i właśnie tak dzieje się w wielu nowoczesnych projektach.
Ja patrzę na to bardzo pragmatycznie: SSR zwykle lepiej sprawdza się tam, gdzie liczą się treści publiczne, indeksacja i szybki pierwszy render, a CSR - w panelach i aplikacjach, w których interakcja jest ważniejsza niż klasyczna nawigacja po dokumentach. W praktyce bardzo dobrze działa układ mieszany: strona marketingowa i listingi z SSR, a panel użytkownika z większą dawką CSR. Dzięki temu nie płaci się za wszystko naraz.
Kiedy te różnice są jasne, dużo łatwiej dobrać architekturę do skali projektu i zespołu, zamiast wybierać modne hasło bez kontekstu.
Jak dobrać model do projektu, zespołu i ruchu
To jest moment, w którym warto odłożyć teorię i zadać kilka prostych pytań. Ja zwykle zaczynam od tego, co zmienia się najczęściej, gdzie są granice domen, ile osób będzie rozwijać system i jak wygląda droga od kodu do produkcji. Dopiero potem decyduję, czy wystarczy monolit modularny, czy naprawdę potrzebne są niezależne usługi.
| Sygnał z projektu | Co to zwykle oznacza | Najrozsądniejszy ruch |
|---|---|---|
| Mały zespół i jedna główna domena biznesowa | Najwięcej zyskasz na prostocie i szybkości zmian | Monolit warstwowy albo modularny |
| Wiele niezależnych obszarów produktu | Różne części systemu mogą mieć własne tempo rozwoju | Moduły z wyraźnymi granicami, a dopiero później ewentualnie mikroserwisy |
| Duży ruch w jednej funkcji, a mały w innych | Jedna część systemu może wymagać osobnego skalowania | Rozdzielenie krytycznego komponentu od reszty, ale bez rozbijania wszystkiego |
| Treści publiczne i SEO są ważne | Liczy się czas pierwszego renderu i indeksacja | SSR albo model mieszany SSR + CSR |
| Zespół nie ma dojrzałych procesów wdrożeniowych | Rozproszona architektura szybko stanie się ciężarem | Unikać mikroserwisów, dopóki nie ma potrzeby i narzędzi do ich obsługi |
Jako heurystykę stosuję prostą zasadę: jeśli nie potrafię wskazać co najmniej trzech wyraźnych, niezależnych domen biznesowych, mikroserwisy zwykle są przedwczesne. To nie jest dogmat, tylko sposób na uniknięcie sytuacji, w której złożoność infrastruktury rośnie szybciej niż wartość biznesowa.
Wybór modelu powinien też uwzględniać kompetencje zespołu. Jeśli ludzie dobrze znają klasyczny rozwój aplikacji i nie mają mocnego zaplecza DevOps, rozsądny monolit modularny często daje lepszy stosunek ryzyka do efektu niż rozproszona architektura, której nikt nie umie diagnozować.
Kiedy już wiesz, jaki ciężar może unieść zespół, czas przejść do konkretnego układu komponentów w typowej aplikacji.
Jak wygląda rozsądny układ dla typowej aplikacji
W praktyce najczęściej projektuję system jako zestaw kilku czytelnych klocków, a nie jako jedną wielką maszynę. Publiczny front może renderować treści po stronie serwera, panel administracyjny może działać bardziej jak aplikacja SPA, a backend trzyma reguły biznesowe, autoryzację i integracje. Taki układ jest czytelny i wystarczająco elastyczny, żeby nie blokować kolejnych zmian.
Przykład, który dobrze to pokazuje, to sklep internetowy. Strona kategorii i opis produktu mogą korzystać z SSR, bo ważne są szybkość wejścia i widoczność w wyszukiwarce. Koszyk i finalizacja zamówienia mogą już działać bardziej interaktywnie, a płatności, wysyłka maili i synchronizacja statusów zamówień lepiej znoszą kolejki i zadania asynchroniczne. Dzięki temu poszczególne części nie przeszkadzają sobie nawzajem.
Przeczytaj również: Funkcje czyste - klucz do lepszego kodu? Przewodnik
Minimalny układ, który zwykle działa
- Frontend - odpowiada za interfejs i komunikację z API.
- API - przyjmuje żądania, pilnuje kontraktów i przekazuje pracę do warstwy aplikacyjnej.
- Warstwa aplikacyjna - składa logikę use case’ów i koordynuje przebieg procesu.
- Warstwa domenowa - trzyma reguły, które nie powinny zależeć od frameworka ani od bazy.
- Warstwa danych - obsługuje zapis, odczyt, migracje i optymalizacje.
- Procesy pomocnicze - wysyłki maili, generowanie raportów, webhooki, synchronizacje.
Ten układ nie jest efektowny, ale jest skuteczny. Właśnie dlatego w wielu projektach daje lepszy zwrot niż rozbudowane rozwiązania wprowadzone za wcześnie.
Gdy taki szkielet jest dobrze ustawiony, najwięcej szkody robią już nie brakujące moduły, tylko codzienne złe nawyki w kodzie i decyzjach zespołu.
Błędy, które psują utrzymanie i rozwój
W architekturze najdroższe są błędy, które wyglądają niewinnie. Na początku dają szybki postęp, ale po kilku miesiącach zamieniają każdą zmianę w serię niespodzianek. Widzę to regularnie: nie chodzi o to, że system był „zły od początku”, tylko o to, że nikt nie pilnował granic i odpowiedzialności.
| Błąd | Jak wygląda w praktyce | Co robię zamiast |
|---|---|---|
| Logika biznesowa w kontrolerach | Każdy endpoint robi trochę wszystkiego, a reguły są porozrzucane | Wyciągam use case’y do warstwy aplikacyjnej i domeny |
| Bezpośredni dostęp do bazy z wielu miejsc | Różne fragmenty systemu obchodzą zasady i tworzą trudne zależności | Wprowadzam jeden kontrolowany punkt dostępu do danych |
| Przedwczesne mikroserwisy | Dużo deploymentów, dużo komunikacji, mało realnej wartości | Zostawiam monolit modularny i rozbijam tylko to, co naprawdę wymaga niezależności |
| Brak obserwowalności | Problem pojawia się w produkcji, a zespół nie wie, gdzie go szukać | Dodaję logi, metryki, korelację requestów i sensowny tracing |
| Zbyt luźne granice modułów | Każdy importuje wszystko, a zmiana jednego fragmentu rozlewa się po projekcie | Wymuszam jasne interfejsy i ograniczam zależności między modułami |
Jeśli miałbym wskazać jeden objaw ostrzegawczy, to byłby nim kod, którego nikt nie potrafi zmienić bez lęku przed skutkami ubocznymi. To zwykle znak, że problemem nie jest framework, tylko brak konsekwentnej struktury i granic odpowiedzialności.
Właśnie dlatego ostatni krok to nie kolejny wzorzec, ale kilka decyzji, które warto zamknąć na samym początku projektu.
Co zaplanować od razu, żeby później nie przepisywać połowy systemu
Najbardziej opłaca się zaplanować to, co będzie najtrudniejsze do zmiany po pół roku. Ja zwracam uwagę przede wszystkim na kontrakty API, granice modułów, sposób logowania zdarzeń oraz strategię wdrożeń. To nie są dodatki. To jest zabezpieczenie przed tym, żeby rozwój produktu nie zamienił się w serię kosztownych przepisań.
- Kontrakty API - jasno opisz zasoby, wersjonowanie i zasady kompatybilności.
- Granice domen - nazwij moduły tak, jak naprawdę działa biznes, a nie tak, jak wygodnie wygląda folder.
- Obsługę błędów - ustal wspólny format odpowiedzi, kody statusów i sposób raportowania problemów.
- Obserwowalność - bez logów, metryk i korelacji requestów produkcja szybko staje się czarną skrzynką.
- Strategię migracji danych - zmiany schematu bazy potrafią unieruchomić nawet dobrze napisany kod.
- Mechanizm wdrożeń - mały, przewidywalny release zwykle daje mniej bólu niż rzadkie, duże skoki.
Jeśli mam zostawić jedną praktyczną wskazówkę, to brzmi ona tak: zaczynaj prosto, ale nie chaotycznie. Dobra struktura nie musi być rozbudowana, żeby była odporna na wzrost. Musi tylko jasno oddzielać odpowiedzialności, ograniczać skutki zmian i pozwalać zespołowi rozwijać produkt bez ciągłego rozbierania go na nowo.