Czyste funkcje to jeden z tych tematów, które szybko zaczynają pracować na jakość całej aplikacji. W praktyce chodzi o funkcję, która dla tych samych danych zawsze zwraca ten sam wynik i nie robi nic poza obliczeniem rezultatu. Taki model ułatwia testy, refaktor i układanie logiki w warstwy, dlatego w architekturze i wzorcach wraca jak bumerang.
Najważniejsze wnioski o funkcjach czystych w kodzie webowym
- Ta sama wartość wejściowa daje ten sam wynik, więc zachowanie funkcji jest przewidywalne.
- Brak efektów ubocznych oznacza brak ukrytych zapisów, odczytów i zmian stanu poza funkcją.
- Najwięcej zyskują na tym transformacje danych, walidacja, selektory i reducery.
- Efekty uboczne warto wypychać na obrzeża systemu: do API, handlerów, warstwy I/O i integracji.
- Czystość nie jest celem samym w sobie, tylko narzędziem do prostszego testowania i bezpieczniejszego refaktoru.
Czym jest funkcja czysta i dlaczego działa przewidywalnie
Definicja jest krótka, ale jej konsekwencje są duże. Funkcja czysta bierze dane wejściowe i na ich podstawie wylicza wynik, nie zapisując niczego „po drodze” do świata zewnętrznego. Microsoft Learn opisuje to bardzo wprost: ten sam input ma dawać ten sam output, bez efektów ubocznych. MDN przypomina przy okazji, że w kodzie warto odróżniać fragmenty, które tylko obliczają wartość, od tych, które coś zmieniają.
| Cecha | Funkcja czysta | Funkcja z efektami ubocznymi |
|---|---|---|
| Wynik | Zależy wyłącznie od argumentów | Może zależeć też od stanu zewnętrznego |
| Stan programu | Nie zmienia go poza zwracanym wynikiem | Może modyfikować obiekty, globalny store, DOM albo bazę |
| Przewidywalność | Ta sama dłoń danych daje ten sam rezultat | Ten sam input nie gwarantuje identycznego zachowania |
| Testowanie | Proste, bo wystarczy podać dane i sprawdzić wynik | Często wymaga mocków, stubów i przygotowania otoczenia |
| Typowe zastosowanie | Obliczenia, walidacja, transformacje, selektory | Sieć, zapis, logowanie, DOM, integracje |
Najbliższe sensowne pojęcie techniczne to referential transparency, czyli możliwość zastąpienia wywołania jego wynikiem bez zmiany znaczenia programu. Gdy funkcja ma tę własność, łatwiej czytać kod jak serię jawnych przekształceń, a nie jak zestaw ukrytych zależności. Właśnie dlatego ten model tak dobrze pasuje do architektury nastawionej na kontrolę przepływu danych.
Sama definicja jest prosta, ale w praktyce ważniejsze jest to, jak rozpoznać ją w konkretnym fragmencie kodu.
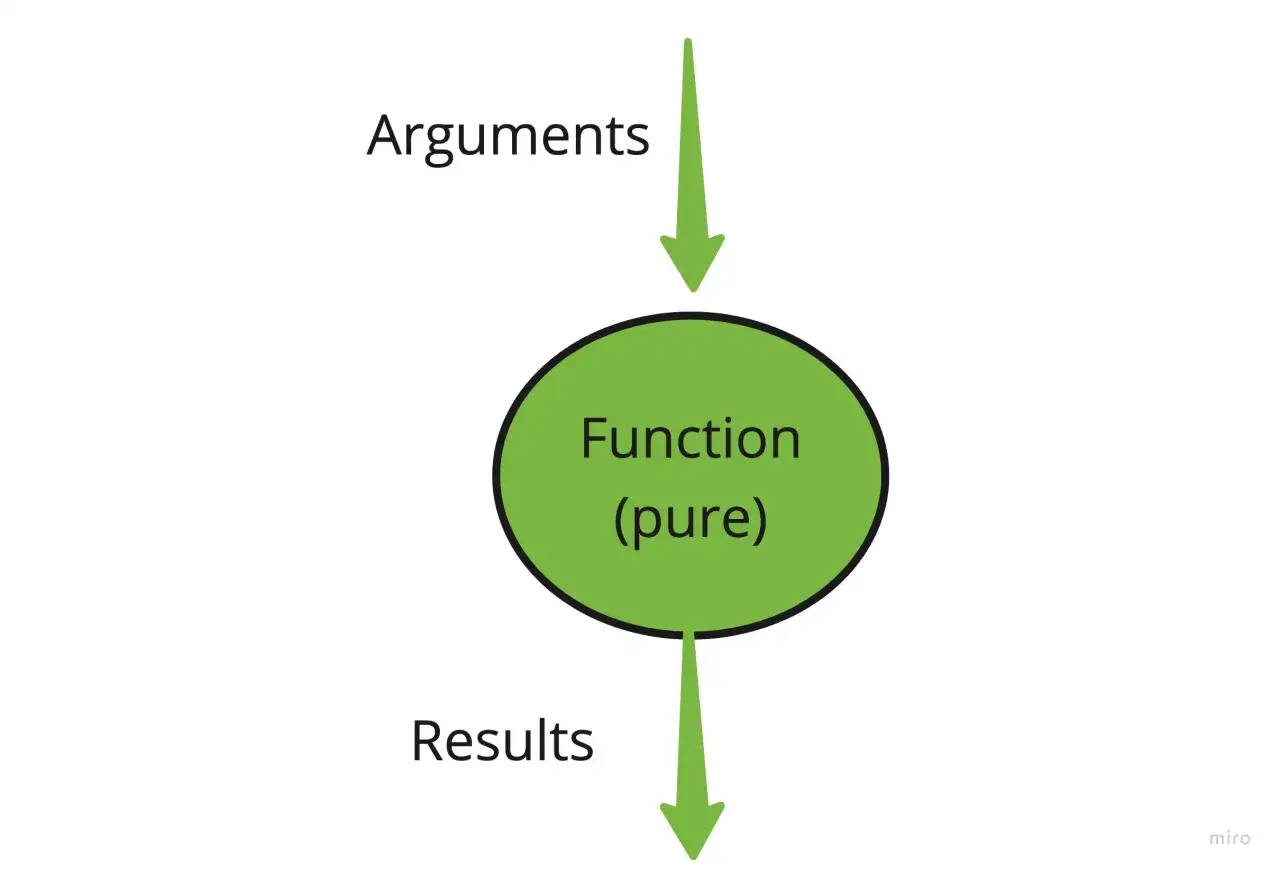
Jak rozpoznać funkcję czystą w kodzie
Ja zwykle zadaję sobie kilka bardzo przyziemnych pytań. Jeśli odpowiedź na większość z nich brzmi „tak, to tylko obliczenie”, mam do czynienia z funkcją czystą albo czymś bardzo bliskim temu wzorcowi.
- Czy funkcja korzysta wyłącznie z argumentów, które dostała na wejściu?
- Czy nie czyta globalnego stanu, `window`, `document` albo zewnętrznego magazynu danych?
- Czy nie modyfikuje przekazanych obiektów lub tablic?
- Czy nie robi I/O, czyli nie zapisuje, nie pobiera i nie wysyła danych?
- Czy nie zależy od czasu, losowości albo kolejności wcześniejszych wywołań?
function sum(a, b) {
return a + b;
}
function addTax(price, taxRate) {
return price * (1 + taxRate);
}Obie funkcje są przewidywalne, bo ich wynik wynika tylko z przekazanych argumentów. Dla kontrastu:
function addToCart(cart, item) {
cart.push(item);
return cart;
}Ta wersja wygląda niewinnie, ale zmienia tablicę przekazaną z zewnątrz. W praktyce to już nie jest czyste obliczenie, tylko mieszanka wyniku i modyfikacji stanu. Jeśli mogę uruchomić funkcję dwa razy z tym samym wejściem i za każdym razem dostać to samo bez ukrytej zmiany w aplikacji, jestem po właściwej stronie granicy.
To prowadzi prosto do pytania, po co w ogóle trzymać taką dyscyplinę w projekcie.
Dlaczego ta zasada wzmacnia architekturę aplikacji
W praktyce zyskuję cztery rzeczy: mniejszą złożoność, łatwiejsze testy, lepszą kompozycję i spokojniejszy refaktor. Czyste funkcje składają się jak klocki, bo nie trzeba zgadywać, co ukrywa się w środku.
- Testy stają się krótsze - podajesz dane wejściowe i sprawdzasz wynik, bez mockowania całego świata.
- Kompozycja jest prostsza - jedną transformację można bezpiecznie podać do drugiej.
- Memoizacja działa naturalnie - skoro wynik zależy tylko od wejścia, można go cache’ować.
- Równoległość jest mniej ryzykowna - brak współdzielonych zmian stanu ogranicza konflikty.
Granica zaczyna się jednak tam, gdzie aplikacja musi wejść w kontakt z prawdziwym światem.
Gdzie czystość przestaje być wygodna
Efekty uboczne nie są z natury złe - są po prostu nieuniknione. Problem zaczyna się wtedy, gdy mieszam je z logiką obliczeniową i później nie wiem, czy błąd dotyczy danych, czy pobocznego zapisu.
| Obszar | Co zwykle psuje czystość | Jak to izolować |
|---|---|---|
| Sieć | Wywołania API, pobieranie danych, retry | Osobny serwis lub warstwa integracji |
| Stan aplikacji | Zapis do store, mutowanie obiektów, globalne zmienne | Jawne argumenty i zwracanie nowej wartości |
| Środowisko | DOM, localStorage, cookies, `window` i `document` | Adapter albo handler na brzegu systemu |
| Czas i losowość | `Date.now()`, `Math.random()`, zależność od bieżącego momentu | Przekazanie wartości jako argumentu |
| Obserwowalność | Logowanie, telemetria, analityka | Oddzielny moduł lub efekt uboczny poza logiką |
Jeśli potrzebuję daty, losowości albo odpowiedzi z API, wolę przekazać je jako argumenty albo pobrać je w warstwie wyżej. Dzięki temu sama funkcja nadal oblicza, a nie orkiestruje. To samo dotyczy wyjątków: w krytycznej logice lepiej zwracać jawny wynik błędu niż opierać się na rzucaniu wyjątków jako części normalnego przepływu.
Kiedy ta granica jest już jasna, łatwiej zaprojektować funkcje tak, żeby wspierały kod, a nie go mieszały.
Jak projektować takie funkcje w aplikacjach webowych
Najlepiej działa u mnie prosta kolejność: najpierw dane, potem transformacja, na końcu efekt uboczny. Dzięki temu warstwa logiki pozostaje stabilna, a integracje można zmieniać bez przepisywania całego środka.
- Przekazuj wszystko jako argumenty - zamiast sięgać do globali, podaj dane jawnie.
- Zwracaj nową wartość - nie modyfikuj tablic i obiektów przekazanych z zewnątrz.
- Oddziel walidację od zapisu - funkcja może sprawdzić dane, ale zapis powinien zrobić inny fragment.
- Wydziel czas i losowość - jeśli ich potrzebujesz, wstrzyknij je z zewnątrz.
- Trzymaj side effects na brzegu systemu - w handlerze, serwisie integracyjnym albo hooku.
function cartReducer(state, action) {
switch (action.type) {
case 'add':
return {
...state,
items: [...state.items, action.item],
};
default:
return state;
}
}To dobry przykład dla Reacta i Reduxa: wynik zależy tylko od `state` i `action`, więc funkcja jest łatwa do testowania i przewidywania. Właśnie dlatego selektory, reducery i większość transformacji danych tak dobrze znoszą czystą postać. Z kolei `useEffect`, obsługa kliknięcia czy zapis do backendu to już miejsce na realny efekt uboczny, a nie na samą logikę obliczenia.
Nawet przy dobrej strukturze łatwo jednak wpaść w kilka powtarzalnych błędów.
Najczęstsze błędy, które psują czystość
- Mutowanie danych wejściowych - `push`, `sort` i bezpośrednia zmiana właściwości obiektu wyglądają jak drobiazg, ale psują przewidywalność.
- Ukryte odczyty stanu globalnego - `window`, `document`, globalny store i zmienne modułowe robią z funkcji zależną od kontekstu.
- Zależność od czasu i losowości - `Date.now()`, `Math.random()` i podobne źródła danych w środku obliczenia utrudniają testy.
- Logowanie i telemetria w środku obliczenia - wygodne na chwilę, kosztowne przy debugowaniu i utrzymaniu.
- Zamiana wyniku na skutek uboczny - funkcja zwraca coś użytecznego, ale po drodze jeszcze zmienia inny fragment programu.
Najbardziej podstępny błąd widzę zwykle tam, gdzie kod wygląda elegancko, ale tylko pozornie: funkcja zwraca nowy obiekt, a w środku i tak dotyka części współdzielonego stanu. To właśnie takie miejsca najtrudniej potem testować, bo wynik bywa poprawny tylko wtedy, gdy cały kontekst też jest „wygodny”.
Dlatego ostatnie pytanie nie brzmi, czy każda funkcja ma być czysta, tylko gdzie ta czystość daje największy zwrot.
Jak wykorzystać tę zasadę bez przesadnej akademickości
Jeśli miałbym wybierać miejsca, od których zaczynam porządkowanie projektu, wskazałbym cztery: walidację formularzy, transformacje danych, selektory stanu i reguły biznesowe. To tam czyste funkcje najszybciej upraszczają kod, bo często pracują na liczbach, stringach i obiektach, czyli na danych, które łatwo opisać testami.
- Walidacja danych wejściowych przed wysłaniem formularza.
- Formatowanie i przeliczanie cen, rabatów, dat lub walut.
- Selekcja i przekształcanie stanu w frontendzie.
- Reguły biznesowe, które nie muszą od razu dotykać bazy ani API.
Nie próbuję natomiast „oczyszczać” wszystkiego na siłę. Integracja z backendem, zapis do storage, analityka czy obsługa zdarzeń pozostaną imperatywne i to jest w porządku. Sens tej zasady polega na tym, żeby część odpowiedzialna za obliczenie była maksymalnie przewidywalna, a reszta kodu miała jasno wyznaczoną rolę. W dobrze poukładanym projekcie właśnie taki podział daje najwięcej spokoju podczas rozwoju i refaktoru.