Maszyna stanów porządkuje procesy, które przechodzą przez jasno zdefiniowane etapy: od utworzenia zamówienia, przez płatność i pakowanie, aż po wysyłkę albo anulowanie. W Springu da się to zrobić tak, żeby logika była czytelna, testowalna i łatwa do rozwijania, ale tylko wtedy, gdy model nie próbuje udawać całego silnika workflow. W tym tekście pokazuję, kiedy taki mechanizm ma sens, jak go zbudować, jak używać guardów, akcji i stanu rozszerzonego oraz kiedy lepiej zatrzymać się przy prostszym rozwiązaniu.
Najważniejsze rzeczy, które warto wiedzieć o maszynie stanów w Springu
- Najlepiej sprawdza się w procesach z wyraźnym cyklem życia, gdzie kolejne stany mają sens biznesowy, a nie tylko techniczny.
- Stan opisuje etap procesu, event wyzwala przejście, guard sprawdza warunek, a action wykonuje efekt uboczny.
- Hierarchia i regiony pomagają modelować bardziej złożone przepływy bez mnożenia ifów i flag.
- Stan rozszerzony służy do danych pomocniczych, które wspierają logikę, ale nie powinny tworzyć osobnych stanów.
- Factory i builder mają sens wtedy, gdy potrzebujesz wielu instancji maszyny albo dynamicznej konfiguracji.
- Persistencja i distributed state są potrzebne dopiero wtedy, gdy proces ma przetrwać restart lub działać na wielu węzłach.
Kiedy maszyna stanów w Springu ma sens, a kiedy tylko komplikuje kod
Ja zwykle zaczynam od prostego pytania: czy proces ma kilka stabilnych etapów i jasne przejścia między nimi. Jeśli odpowiedź brzmi „tak”, to masz dobry kandydat na model stanów. Jeśli nie, bardzo możliwe, że wystarczy zwykły serwis, kilka metod i odrobina walidacji.
W dokumentacji Spring Statemachine widać, że to raczej fundament niż pełny silnik workflow. I właśnie tak bym to traktował: jako narzędzie do porządkowania logiki domenowej, a nie jako warstwę, którą dokłada się „na wszelki wypadek”.
- Dobry przypadek to zamówienie, reklamacja, onboarding użytkownika, akceptacja dokumentu albo subskrypcja z etapami aktywacji.
- Słabszy przypadek to prosty CRUD, gdzie status jest tylko etykietą w bazie i niczego realnie nie steruje.
- Sygnał ostrzegawczy pojawia się wtedy, gdy dodajesz kolejne flagi tylko po to, żeby obsłużyć wyjątki w if/else.
Jeżeli masz proces, który da się opisać jako „zawsze najpierw X, potem czasem Y, a na końcu Z”, to jesteś blisko właściwego zastosowania. Jeśli kolejne kroki zależą od coraz większej liczby kombinacji, lepiej najpierw uprościć model biznesowy, a dopiero potem wybierać technologię. To prowadzi wprost do pytania, jak taki model powinien wyglądać w kodzie.
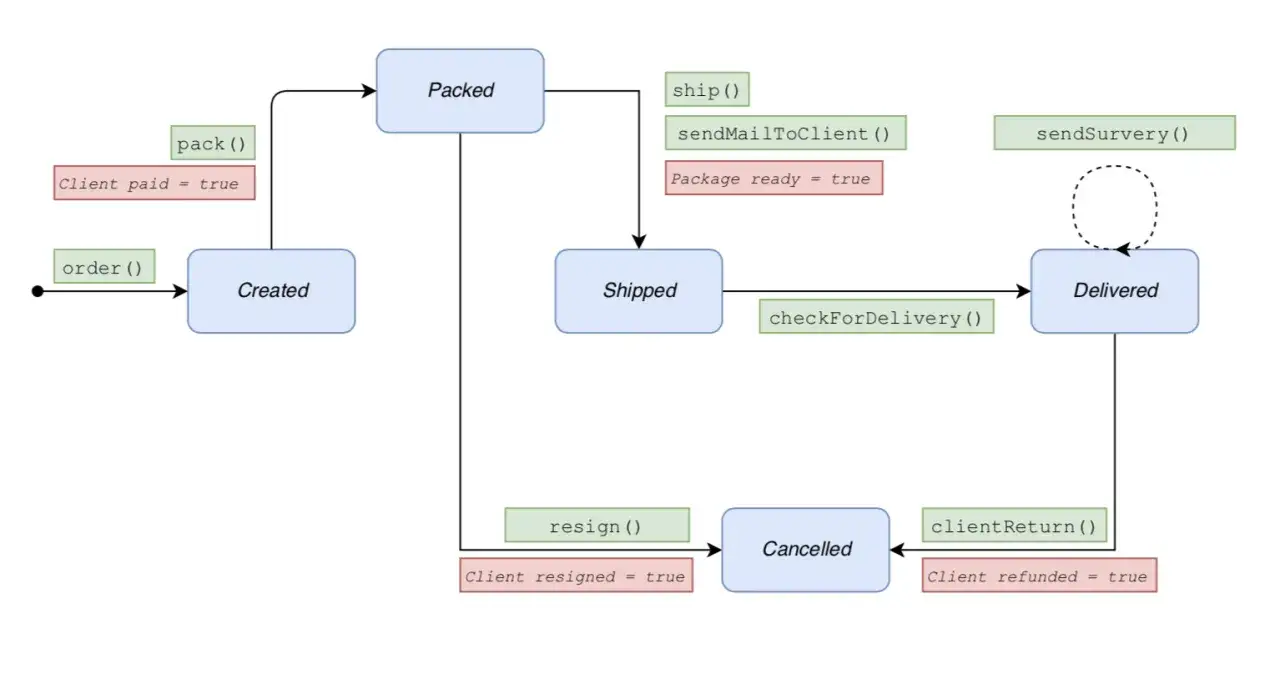
Jak wygląda prosty model stanów i przejść
Najprostszy układ składa się z czterech elementów: stanów, zdarzeń, przejść i akcji. Stan mówi, gdzie proces aktualnie się znajduje. Zdarzenie mówi, co się wydarzyło. Przejście łączy oba punkty. Akcja robi coś dodatkowego, na przykład zapisuje dane, publikuje komunikat albo aktualizuje licznik.
Poniżej pokazuję minimalny przykład dla zamówienia. To nie jest produkcyjny szablon, tylko czytelny punkt startowy, który dobrze wyjaśnia logikę.
@Configuration
@EnableStateMachine
public class OrderMachineConfig extends EnumStateMachineConfigurerAdapter {
@Override
public void configure(StateMachineStateConfigurer states) throws Exception {
states
.withStates()
.initial(OrderState.NEW)
.state(OrderState.PAID)
.state(OrderState.PACKING)
.end(OrderState.SHIPPED)
.end(OrderState.CANCELED);
}
@Override
public void configure(StateMachineTransitionConfigurer transitions) throws Exception {
transitions
.withExternal().source(OrderState.NEW).target(OrderState.PAID).event(OrderEvent.PAY)
.and()
.withExternal().source(OrderState.PAID).target(OrderState.PACKING).event(OrderEvent.PACK)
.and()
.withExternal().source(OrderState.PACKING).target(OrderState.SHIPPED).event(OrderEvent.SHIP)
.and()
.withExternal().source(OrderState.PAID).target(OrderState.CANCELED).event(OrderEvent.CANCEL);
}
} stateMachine.sendEvent(
Mono.just(MessageBuilder.withPayload(OrderEvent.PAY).build())
).subscribe();To jest dobry moment, żeby podkreślić jedną rzecz: każdy stan powinien coś wyjaśniać biznesowo. Jeśli stan nie wnosi nic poza technicznym „może kiedyś się przyda”, to zwykle oznacza, że model jest zbyt drobno pocięty. Ja wolę mniej stanów, ale za to takich, które da się obronić przed zespołem i przed przyszłym sobą.
Gdy podstawowy model już działa, naturalnie pojawia się pytanie, jak ogarnąć przepływy większe niż prosta lista przejść. I tu wchodzą hierarchia oraz regiony.
Jak skalować model przez hierarchię i regiony
Jeżeli proces zaczyna się rozrastać, nie dodawaj od razu kolejnych statusów „na wszelki wypadek”. Dużo lepiej działa hierarchia, czyli stan nadrzędny z podstanami, oraz regiony, czyli niezależne tory przetwarzania wewnątrz jednego modelu. To właśnie one ratują architekturę wtedy, gdy jedna płaska maszyna zaczyna przypominać tablicę pełną wyjątków.
| Model | Kiedy użyć | Co daje | Ryzyko |
|---|---|---|---|
| Flat | Prosty proces z kilkoma etapami | Najłatwiejszy do przeczytania i przetestowania | Szybko puchnie, jeśli proces ma wiele wyjątków |
| Hierarchical | Masz wspólne zachowanie dla grupy podstanów | Mniej duplikacji i lepszy porządek w regułach | Większa abstrakcja, więc trudniej zacząć bez dobrego modelu domeny |
| Regions | Dwa lub więcej niezależnych torów dziejących się równolegle | Możesz modelować np. płatność i realizację bez wciskania ich do jednego łańcucha | Debugowanie bywa trudniejsze, bo trzeba śledzić kilka aktywnych gałęzi naraz |
Praktyczny przykład jest prosty: zamówienie może mieć osobny tor płatności i osobny tor realizacji. Wtedy nie próbuję upychać wszystkiego w jeden ciąg statusów, bo to zwykle kończy się chaosem. Regiony pozwalają mi powiedzieć: te dwa obszary są logicznie związane, ale nie muszą się blokować nawzajem.
Hierarchia przydaje się z kolei wtedy, gdy kilka podstanów dzieli wspólną logikę. Zamiast powtarzać te same przejścia w trzech miejscach, przenoszę je wyżej. Efekt jest prosty: mniej kopiowania, mniej rozjazdów i łatwiejsze utrzymanie. Następny krok to rozdzielenie samej logiki przejścia od warunków i efektów ubocznych.
Guardy, akcje i stan rozszerzony bez mieszania odpowiedzialności
Tu najłatwiej o błąd, bo te trzy elementy wyglądają podobnie tylko na pierwszy rzut oka. Guard odpowiada na pytanie „czy wolno przejść dalej”. Action robi konkretne działanie przy wejściu, wyjściu albo w trakcie przejścia. Extended state przechowuje dane pomocnicze, które wspierają logikę, ale same nie są nowymi stanami.
- Guard używaj do czystej decyzji: tak albo nie, bez zapisu do bazy i bez wysyłania wiadomości.
- Action trzymaj dla efektów ubocznych: zapisów, integracji, publikacji eventów, logowania audytowego.
- Extended state wykorzystuj do liczników, identyfikatorów roboczych, flag pomocniczych i danych wejściowych do kolejnego kroku.
Jeśli masz regułę typu „przejdź dalej tylko wtedy, gdy magazyn ma towar i płatność została potwierdzona”, guard jest dobrym miejscem na ocenę warunku. Jeśli po przejściu trzeba zarezerwować towar i wysłać wiadomość do innego systemu, to już jest praca dla action. Ja zawsze pilnuję tej granicy, bo inaczej logika zaczyna się rozlewać po kilku warstwach naraz.
Stan rozszerzony przydaje się wtedy, gdy ktoś próbuje stworzyć osobny stan dla każdej liczby, flagi albo wariantu danych. W dokumentacji Spring Statemachine jest to pokazane bardzo dobrze: zamiast mnożyć stany, lepiej przechowywać zmienne pomocnicze i aktualizować je w trakcie przejścia. To zwykle daje czytelniejszy model i mniejszą liczbę przejść do utrzymania. Gdy już wiesz, co modelować, zostaje wybór sposobu konfiguracji.
Jak wybrać między adnotacjami, fabryką i builderem
Spring daje kilka ścieżek konfiguracji i tu nie ma jedynej słusznej odpowiedzi. Ja patrzę na to przez pryzmat liczby instancji, zmienności konfiguracji i tego, czy maszyna ma powstawać wprost z kontekstu Springa, czy raczej dynamicznie.
| Podejście | Kiedy ma sens | Plusy | Ograniczenia |
|---|---|---|---|
@EnableStateMachine |
Jedna maszyna lub bardzo prosty scenariusz | Najczytelniejsze wejście, naturalne w Springu, dobre typowanie na enumach | Mniej elastyczne, gdy konfiguracja ma się zmieniać w czasie działania |
@EnableStateMachineFactory |
Wiele instancji tego samego workflow, np. zamówienia albo sesje użytkowników | Możesz tworzyć nowe maszyny na żądanie, a konfiguracja nadal pozostaje spójna | W dokumentacji jest wskazane ograniczenie: akcje i guardy współdzielą te same instancje beanów, więc trzeba uważać na stan mutowalny |
| Builder | Potrzebujesz dynamicznie tworzyć maszyny poza pełnym kontekstem Springa | Duża elastyczność, przydatna w testach i w bardziej dynamicznych scenariuszach | Więcej ręcznego kodu i łatwiej go nadużyć |
W aplikacji webowej najczęściej wygrywa prosty układ: kontroler przyjmuje żądanie, serwis decyduje o evencie, a sama maszyna pozostaje osobnym komponentem domenowym. W aktualnym API dobrze jest myśleć reaktywnie, czyli wysyłać eventy w stylu sendEvent(Mono.just(...)), zamiast przywiązywać się do dawnych, bardziej blokujących przyzwyczajeń. To porządkuje integrację, zwłaszcza gdy aplikacja już i tak korzysta z reaktywnego stosu. Jeśli jednak proces ma żyć dłużej niż pojedynczy request, trzeba pomyśleć o zapisie stanu.
Persistencja, machineId i rozproszony scenariusz tylko wtedy, gdy naprawdę ich potrzebujesz
Dokumentacja Spring Statemachine pokazuje persystencję na JPA, Redis i MongoDB, ale ja traktuję to jako narzędzie dla konkretnych problemów, nie jako domyślny etap wdrożenia. Najpierw zadaję pytanie: czy proces musi przetrwać restart, czy wystarczy stan w pamięci? Dopiero później dochodzą identyfikator maszyny i ewentualna dystrybucja.
- Potrzebujesz restart-resume - użyj persystencji, żeby wrócić do tego samego stanu po awarii albo redeployu.
-
Masz wiele równoległych instancji - nadaj sensowny
machineId, bo bez tego logi i debugowanie szybko stają się męczące. - Chcesz synchronizować stan między węzłami - rozważ model rozproszony tylko wtedy, gdy naprawdę masz na to biznesowe uzasadnienie i repozytorium o silnej spójności.
machineId. Skoro mowa o utrzymaniu, warto od razu przejść do tego, co najczęściej psuje czytelność i testowalność modelu.
Najczęstsze błędy i jak je łapać w testach
Najwięcej problemów widzę nie w samej technologii, tylko w sposobie modelowania. Maszyna stanów potrafi wyglądać elegancko na diagramie, a po miesiącu rozwoju zamienić się w trudny do zrozumienia układ wyjątków. Ja zwykle sprawdzam pięć rzeczy.
- Za dużo flag zamiast stanów - jeśli logika zależy od kombinacji booleanów, model jest zwykle źle rozcięty.
- Efekty uboczne w guardach - guard ma decydować, nie zapisywać, nie wysyłać maili i nie aktualizować kilku systemów naraz.
- Jedna instancja do wielu niezależnych procesów - to kusi na początku, ale później komplikuje współbieżność i debugowanie.
- Brak testów negatywnych - warto testować nie tylko happy path, ale też eventy odrzucone przez guardy i przejścia niedozwolone.
- Zbyt anonimowe extended state - jeśli w zmiennej pomocniczej nie widać sensu biznesowego, ktoś za tydzień nie zrozumie, po co ona istnieje.
Ja najczęściej testuję trzy scenariusze: stan początkowy, poprawne przejście i blokadę przez guard. To wystarcza, żeby szybko wyłapać większość błędów w konfiguracji. Do tego dorzucam sprawdzenie, czy action faktycznie wykonała się tylko wtedy, gdy przejście zostało zaakceptowane. Taki zestaw daje dużo lepszą ochronę niż sama wizualna kontrola diagramu. Jeśli te testy zaczynają boleć, to często znak, że model stanów jest zbyt skomplikowany i trzeba go jeszcze raz uprościć.
Jak utrzymać model stanów czytelny po miesiącach rozwoju
Najlepszy efekt daje podejście bez przesady: modeluję tylko to, co naprawdę jest etapem procesu, a resztę trzymam w danych pomocniczych albo zwykłej logice serwisowej. Dzięki temu maszyna stanów pozostaje narzędziem do porządkowania architektury, a nie kolejną warstwą, którą trzeba omijać szerokim łukiem.
Jeśli proces jest prosty, zostaw go prostym. Jeśli rośnie, dołóż hierarchię, guardy i persystencję tylko tam, gdzie rozwiązują konkretny problem. To właśnie wtedy Spring Statemachine daje największą wartość: nie jako ozdoba w projekcie, ale jako sposób na to, żeby przepływ biznesowy był przewidywalny, testowalny i czytelny także dla osoby, która wróci do kodu za pół roku.