
Dobry kod to nie tylko taki, który działa, ale też taki, który nie zwalnia dramatycznie, gdy danych przybywa. W tym tekście wyjaśniam, czym jest złożoność obliczeniowa algorytmów, jak odróżnić koszt czasu od kosztu pamięci i jak w praktyce ocenić, czy rozwiązanie nadaje się do małych, czy do dużych zbiorów danych. Pokażę też najczęstsze pułapki i proste reguły, które pomagają początkującym czytać kod bez zgadywania.
Najważniejsze rzeczy, które musisz wiedzieć od razu
- Złożoność opisuje, jak rosną wymagania programu wraz ze wzrostem danych wejściowych, a nie ile dokładnie sekund kod działa na jednym komputerze.
- Najczęściej patrzy się na dwa aspekty: czas i pamięć.
- Notacja duże O pomaga porównywać rozwiązania niezależnie od sprzętu i języka, ale nie zastępuje zdrowego rozsądku przy małych danych.
- Dwie pętle zagnieżdżone zwykle oznaczają koszt kwadratowy, a wyszukiwanie połówkowe w posortowanych danych daje dużo lepszą skalowalność niż liniowe skanowanie.
- Najczęstszy błąd początkujących to mylenie szybkiego kodu na próbce testowej z kodem, który dobrze skaluje się do większego obciążenia.
Co naprawdę mierzy ten wskaźnik
Analiza złożoności nie pyta, czy program uruchomił się w 0,02 sekundy czy w 0,2 sekundy na moim laptopie. Pyta o coś ważniejszego: jak zmieni się koszt działania, gdy rozmiar danych wzrośnie. Dlatego ten sam algorytm może być świetny dla kilkudziesięciu rekordów, a słaby dla miliona.
W praktyce rozróżniam dwa poziomy oceny. Złożoność czasowa mówi, ile pracy wykonuje program, a złożoność pamięciowa pokazuje, ile dodatkowej pamięci potrzebuje, by wykonać zadanie. Przy prostych projektach webowych oba parametry potrafią boleć jednocześnie, zwłaszcza gdy przetwarzasz duże tablice, JSON-y albo działasz w przeglądarce z ograniczonym RAM-em.| Rodzaj złożoności | Co mierzy | Jak czytać to w praktyce |
|---|---|---|
| Czasowa | Liczbę operacji potrzebnych do wykonania zadania | Czy kod zwalnia, gdy danych robi się 10 razy więcej |
| Pamięciowa | Dodatkową pamięć zużytą podczas działania | Czy rozwiązanie zmieści się w pamięci urządzenia i nie zablokuje aplikacji |
Ja zwykle zaczynam od pytania, co jest w danym zadaniu wąskim gardłem. Jeśli operacje są tanie, ale danych jest dużo, skupiam się na czasie. Jeśli dane są ciężkie, a środowisko mało zasobne, ważniejsza staje się pamięć. To prowadzi naturalnie do notacji, którą najczęściej spotkasz w praktyce.
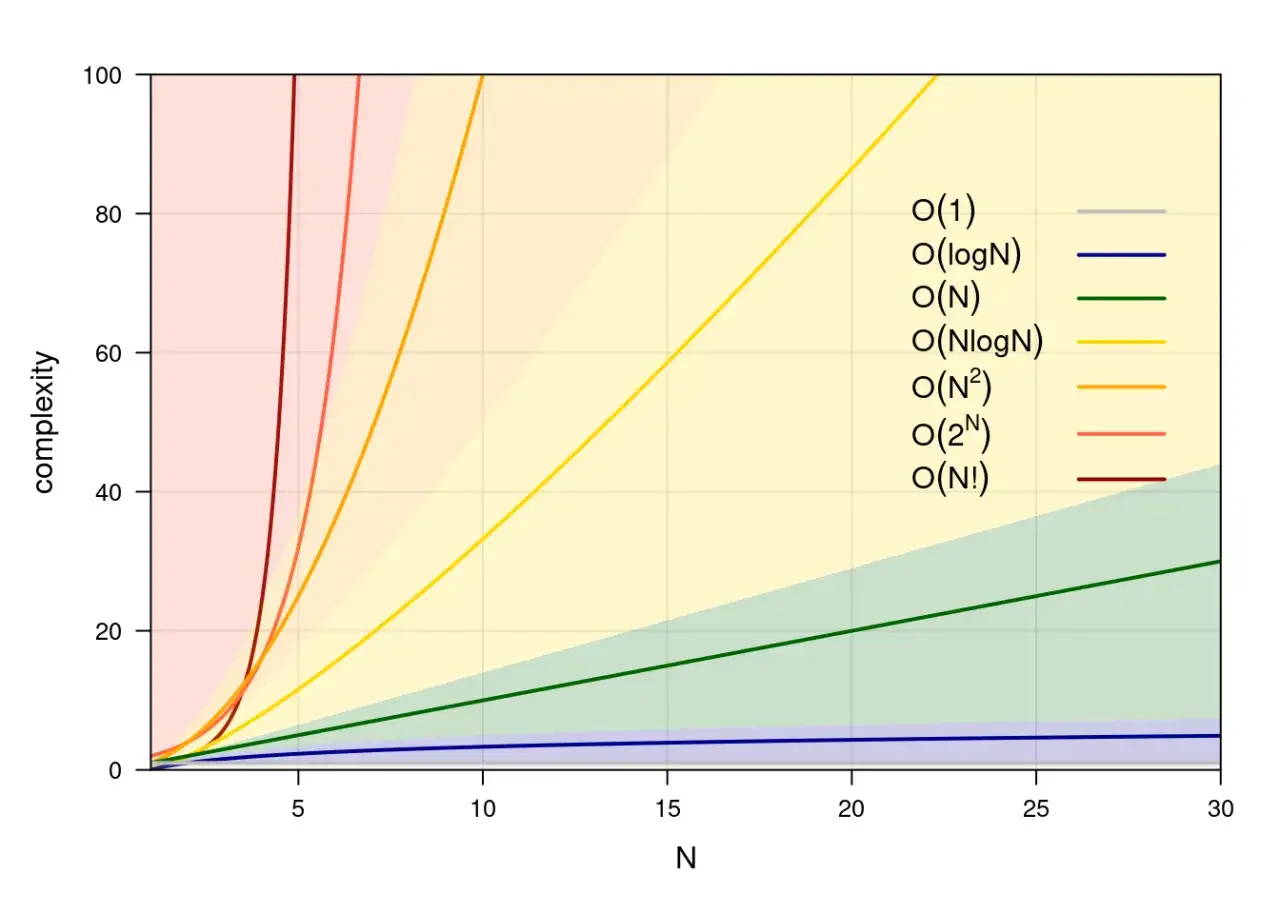
Jak czytać notację Big O w codziennym kodzie
Duże O opisuje, jak rośnie koszt wraz z rozmiarem danych, a nie precyzyjny czas wykonania. Dla początkującego to ważne od razu, bo łatwo pomylić „szybki na próbkach” z „dobrze skalujący się”. W analizie pomija się stałe i mniej istotne składniki, żeby zobaczyć sam trend wzrostu.
| Rząd złożoności | Co oznacza intuicyjnie | Typowy przykład |
|---|---|---|
| O(1) | Koszt prawie nie zależy od rozmiaru danych | Odczyt elementu po indeksie |
| O(log n) | Każde podwojenie danych dodaje bardzo mało pracy | Wyszukiwanie binarne w posortowanej tablicy |
| O(n) | Koszt rośnie proporcjonalnie do liczby elementów | Jedno przejście po tablicy |
| O(n log n) | Rosnie szybciej niż liniowo, ale nadal rozsądnie | Wiele dobrych algorytmów sortowania |
| O(n²) | Przy większych danych koszt rośnie bardzo gwałtownie | Dwie zagnieżdżone pętle po tej samej kolekcji |
Najbardziej użyteczna reguła jest prosta: jeśli podwoisz dane, algorytm O(n) zwykle zrobi około 2 razy więcej pracy, a O(n²) około 4 razy więcej. Przy 10-krotnym wzroście danych różnica robi się brutalna, bo liniowe rozwiązanie rośnie 10 razy, a kwadratowe już około 100 razy. Dlatego przy większych zbiorach danych nawet „niewinne” decyzje w kodzie potrafią zmienić się w realny problem wydajnościowy.
W praktyce nie warto też ślepo traktować dużego O jako wyroczni. Dwa algorytmy mogą mieć ten sam rząd złożoności, a jeden nadal będzie wyraźnie szybszy przez mniejszy narzut, lepszą pamięć podręczną albo prostsze operacje wewnętrzne. To właśnie dlatego analiza asymptotyczna daje kierunek, ale nie zastępuje testów na realnych danych.
Żeby nie mieszać teorii z praktyką, dobrze odróżnić samą klasę wzrostu od sposobu, w jaki kod zużywa zasoby. To prowadzi do najważniejszego kompromisu w programowaniu.
Czas i pamięć rzadko rosną tak samo
W realnym kodzie prawie zawsze coś kosztem czegoś. Szybsze rozwiązanie często trzyma więcej danych w pamięci, a oszczędniejsze pamięciowo bywa wolniejsze, bo musi częściej czytać albo przeliczać informacje. Przy małych projektach to detal, przy większych już decyzja architektoniczna.
Dobry przykład to sortowanie. Jedne algorytmy sortujące wykorzystują dodatkową pamięć, ale dają przewidywalny czas działania. Inne próbują działać „na miejscu”, czyli bez dużych buforów pomocniczych, ale bywają trudniejsze do zrozumienia i w pewnych przypadkach mają gorsze zachowanie. Podobny kompromis widać przy przetwarzaniu dużych plików: można wczytać wszystko do pamięci i pisać prostszy kod, ale można też streamować dane kawałkami i oszczędzić RAM.
- Rekurencja zwykle zwiększa zużycie pamięci, bo każde wywołanie trafia na stos.
- Buforowanie przyspiesza odczyt, ale zwiększa pamięć zajętą przez program.
- Struktury haszujące często poprawiają czas wyszukiwania, ale płacisz za to dodatkowym narzutem pamięciowym.
- Przetwarzanie strumieniowe pomaga przy dużych danych, ale kod bywa mniej wygodny niż prosty model „wczytaj wszystko i obrabiaj”.
W środowisku webowym to szczególnie ważne, bo przeglądarka nie wybacza lekkiego przegięcia z pamięcią tak łatwo, jak lokalny skrypt na niewielkich danych. Z tego powodu warto umieć nie tylko ocenić czas działania, ale też przewidzieć koszt pamięci jeszcze przed napisaniem dłuższej funkcji.
Jak samodzielnie oszacować koszt algorytmu
Ja zwykle liczę złożoność w czterech krokach. Najpierw patrzę na liczbę pętli, potem na to, czy są zagnieżdżone, później sprawdzam rekurencję, a na końcu szukam ukrytych kosztów w operacjach na strukturach danych. Brzmi szkolnie, ale działa zaskakująco dobrze nawet w prostych projektach.
- Sprawdź, ile razy wykonywany jest główny blok kodu.
- Jeśli widzisz pętle w pętlach, pomnóż ich koszty zamiast liczyć je osobno.
- Przy rekurencji policz liczbę wywołań i koszt pracy wykonanej w każdym wywołaniu.
- Ustal, czy operacje na tablicy, mapie albo liście są stałe, liniowe czy zależne od implementacji.
// O(n)
for (let i = 0; i < items.length; i++) {
total += items[i];
}
// O(n²)
for (let i = 0; i < items.length; i++) {
for (let j = 0; j < items.length; j++) {
compare(items[i], items[j]);
}
}W pierwszym przykładzie każdemu elementowi poświęcasz stałą ilość pracy, więc koszt rośnie liniowo. W drugim każda iteracja zewnętrzna uruchamia pełny przebieg pętli wewnętrznej, więc rośnie koszt kwadratowy. To różnica, która przy 1 000 elementów może być jeszcze tolerowana, ale przy 100 000 elementów staje się problemem praktycznym, nie akademickim.
Trzeba też uważać na rekurencję. Jeśli funkcja woła samą siebie raz na poziom, a głębokość zależy od rozmiaru danych, pojawia się dodatkowy koszt pamięci na stos wywołań. W JavaScripcie i w przeglądarce to ma znaczenie szybciej, niż wielu początkujących zakłada. Dlatego analiza złożoności nie kończy się na policzeniu pętli.
Najwięcej błędów nie bierze się z samej teorii, tylko z kilku powtarzalnych skrótów myślowych. Właśnie one najczęściej psują ocenę kodu.
Najczęstsze błędy początkujących
Najczęstszy błąd, który widzę, to ocenianie kodu wyłącznie po tym, jak działa na małej próbce. Kod może wyglądać świetnie dla 20 elementów i rozjechać się przy 20 000. Drugie częste potknięcie to mylenie złożoności asymptotycznej z faktycznym czasem na jednym komputerze. To nie to samo.
- Ignorowanie stałych bywa mylące, bo przy małych danych czasem szybszy okazuje się prostszy kod o gorszym rzędzie wzrostu.
- Patrzenie tylko na przypadek średni bez rozumienia najgorszego scenariusza prowadzi do niemiłych niespodzianek w produkcji.
- Zakładanie, że każda operacja na tablicy kosztuje tyle samo jest zbyt uproszczone, bo zależy to od metody i implementacji.
- Pomijanie pamięci jest ryzykowne w kodzie, który obrabia dużo danych lub używa rekurencji.
- Optymalizacja zbyt wcześnie często kończy się skomplikowanym kodem bez realnego zysku.
W praktyce wolę najpierw zrozumieć, jak algorytm skaluje się do większego obciążenia, a dopiero potem szukać drobnych usprawnień. To lepsza kolejność niż odwrotna, bo najpierw eliminuje się błędy rzędu, a dopiero później stroi detale.
Jak przełożyć to na lepszy kod i lepszą naukę
Jeśli dopiero uczysz się programowania, traktuj analizę złożoności jak narzędzie do myślenia, a nie egzamin z matematyki. Najpierw wybierz rozwiązanie poprawne i czytelne, a potem sprawdź, czy nie ma prostszej struktury danych albo lepszego sposobu przejścia po danych. To podejście uczy dobrych nawyków bez wpędzania się w sztuczną perfekcję.
Przy zadaniach z listami i tablicami pytam siebie o trzy rzeczy: czy potrzebuję szybkiego odczytu, czy częstych wstawień, czy może dużo wyszukiwań. Jeśli wyszukiwań jest dużo, struktura haszująca zwykle wygrywa z ręcznym skanowaniem. Jeśli ważny jest porządek, tablica albo lista posortowana może być lepszym kompromisem. Taka decyzja nie opiera się na modzie, tylko na kosztach operacji.
Najbardziej praktyczna zasada brzmi tak: nie optymalizuj w ciemno, ale też nie ignoruj wzrostu danych. Gdy kod ma obsłużyć większy ruch, większy katalog produktów albo większe pliki, złożoność przestaje być teorią, a staje się granicą między rozwiązaniem stabilnym a takim, które zaraz trzeba przepisywać. Jeśli zapamiętasz tylko jedną rzecz, niech będzie nią to, że dobre rozwiązanie to nie zawsze najszybsze rozwiązanie na małej próbce, lecz to, które zachowuje sensowną wydajność także wtedy, gdy skala zaczyna naprawdę rosnąć.