
Gdy liczba danych rośnie, szybko wychodzi na jaw, czy kod skaluje się rozsądnie, czy tylko dobrze wygląda na małych testach. Właśnie do tego służy notacja o, czyli praktycznie notacja Big O: pokazuje, jak rosną czas działania i zużycie pamięci wraz z wielkością problemu. W tym tekście wyjaśniam ją bez akademickiego nadęcia, na prostych przykładach z programowania i z naciskiem na to, co naprawdę przydaje się początkującej osobie.
Najważniejsze rzeczy o wielkim O, które warto zapamiętać
- Big O opisuje tempo wzrostu kosztu algorytmu, a nie dokładny czas w milisekundach.
- Najczęściej spotkasz klasy: O(1), O(log n), O(n), O(n log n), O(n^2) i O(2^n).
- Jedna pętla zwykle daje koszt liniowy, a pętle zagnieżdżone bardzo szybko podnoszą złożoność.
- Big O dotyczy nie tylko czasu, ale też pamięci, co w praktyce bywa równie ważne.
- Przy małych danych różnice mogą być niewielkie, ale przy dużych zbiorach stają się ogromne.
Co naprawdę opisuje wielkie O
Ja zwykle tłumaczę to tak: Big O nie mówi, ile dokładnie trwa program, tylko jak rośnie jego koszt, kiedy rośnie rozmiar danych. To pojęcie asymptotyczne, więc interesuje nas zachowanie algorytmu „w dłuższym biegu”, a nie pojedynczy wynik na jednym komputerze.
Najważniejsza rzecz, którą trzeba od razu zrozumieć, brzmi: Big O pomija stałe i drobne składniki, bo przy dużych danych dominują one coraz mniej. Jeśli masz funkcję typu 4n^2 - 2n + 2, to z punktu widzenia złożoności patrzysz przede wszystkim na n^2. Dlatego zapis O(n^2) mówi więcej o skali niż o szczegółach implementacji.
To także powód, dla którego Big O często wiąże się z górnym ograniczeniem. W praktyce programiści używają go jako szybkiej odpowiedzi na pytanie: czy ten algorytm będzie nadal sensowny, gdy danych będzie dziesięć, sto albo tysiąc razy więcej? Kiedy już to rozumiesz, dużo łatwiej porównać konkretne klasy złożoności. Następny krok to zobaczenie ich na liczbach i przykładach.
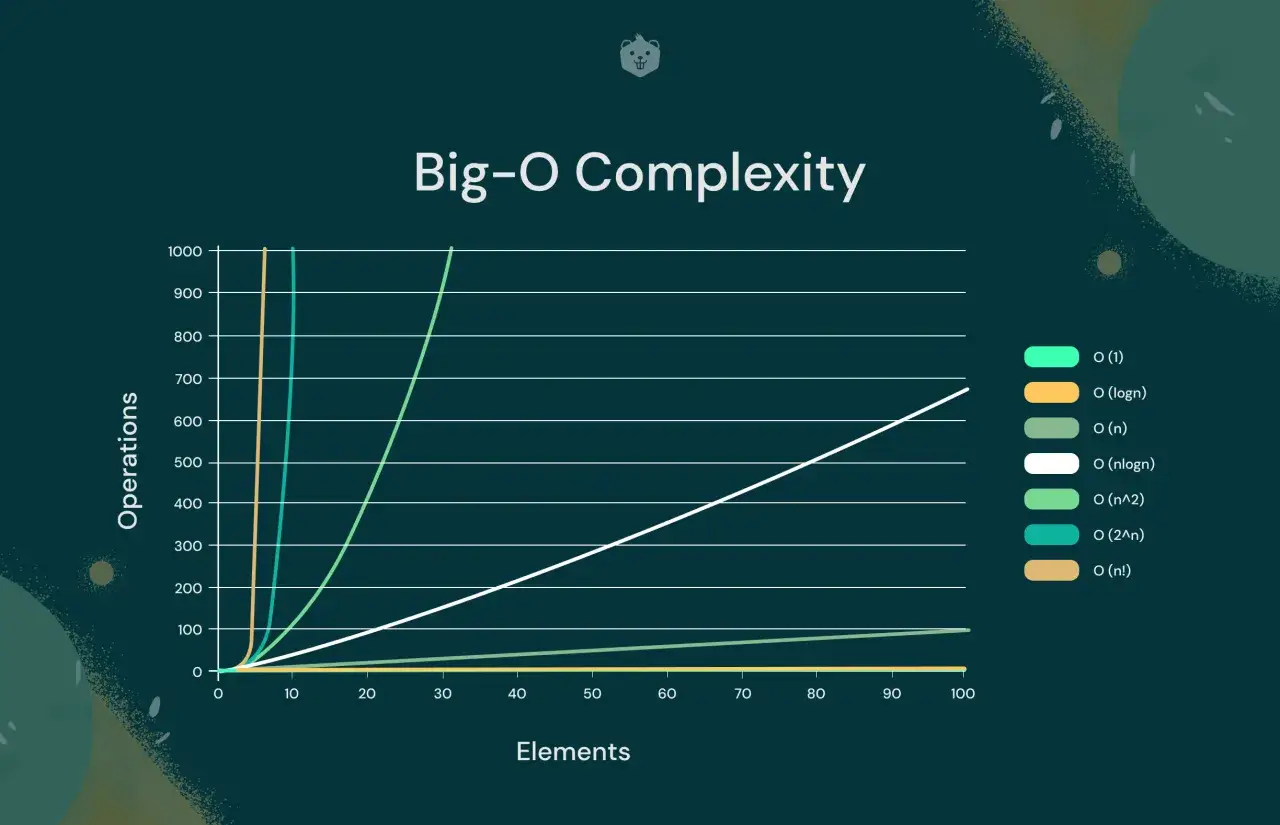
Najczęstsze klasy złożoności i jak je rozpoznawać
W praktyce nie trzeba znać dziesiątek oznaczeń. Na start wystarczy kilka klas, które pojawiają się niemal wszędzie. Warto je kojarzyć nie tylko po nazwie, ale też po zachowaniu kodu.
| Złożoność | Co oznacza w praktyce | Przykład | Kiedy to zwykle ma sens |
|---|---|---|---|
| O(1) | Koszt nie rośnie wraz z liczbą danych. | Pobranie elementu po indeksie. | Gdy potrzebujesz bardzo szybkiego, przewidywalnego dostępu. |
| O(log n) | Każdy krok mocno zmniejsza problem. | Wyszukiwanie binarne w posortowanej tablicy. | Przy dużych zbiorach i danych uporządkowanych. |
| O(n) | Trzeba przejść przez dane raz. | Znajdowanie największej wartości w tablicy. | To często najlepszy kompromis między prostotą a skalowaniem. |
| O(n log n) | Rosną szybkość i koszt umiarkowanie. | Sortowanie przez scalanie, szybkie sortowanie w typowym przypadku. | Gdy zależy ci na dobrej wydajności przy większych danych. |
| O(n^2) | Koszt rośnie gwałtownie, gdy dane przybywają. | Porównywanie każdej pary elementów. | Najczęściej tylko dla małych zbiorów albo prostych zadań. |
| O(2^n) | Liczba możliwości rośnie lawinowo. | Brute force przy wszystkich podzbiorach. | Zazwyczaj tylko dla bardzo małych wartości n. |
Na liczbach różnica robi się brutalnie widoczna. Dla 1 000 000 elementów wyszukiwanie binarne to około 20 porównań, bo 2^20 przekracza milion, podczas gdy liniowe przejście może wymagać aż 1 000 000 kroków. Z kolei n^2 daje w uproszczeniu 10^12 operacji, czyli skalę zupełnie nieporównywalną z poprzednimi przypadkami.
To dlatego dwie implementacje, które na małej próbce wyglądają podobnie, po wzroście danych zaczynają się zachowywać kompletnie inaczej. Gdy umiesz już rozpoznawać klasy złożoności, warto zobaczyć, jak wylicza się je z prostego kodu. Wtedy notacja przestaje być abstrakcją, a zaczyna być narzędziem.
Jak liczyć złożoność prostych fragmentów kodu
Ja zwykle patrzę na kod przez trzy pytania: ile razy wykonuje się operacja, czy pętle się zagnieżdżają i czy problem dzieli się na mniejsze części. To wystarcza, żeby oszacować większość przypadków spotykanych na początku nauki.
Jedna pętla zwykle oznacza O(n)
Jeśli przechodzisz po każdym elemencie raz, koszt rośnie liniowo. W JavaScript wygląda to na przykład tak:
let sum = 0;
for (let i = 0; i < arr.length; i++) {
sum += arr[i];
}Tu nie ma żadnej sztuczki: każdy element jest odwiedzany jeden raz. Jeśli tablica ma 100 elementów, wykonujesz około 100 iteracji; jeśli 10 000, to około 10 000. To klasyczne O(n).
Dwie pętle po sobie nadal dają O(n)
To częsty punkt nieporozumienia. Gdy jedna pętla kończy się, a druga startuje potem, koszty się sumują, a nie mnożą. Dlatego taki kod nadal jest liniowy:
for (let i = 0; i < arr.length; i++) {
// coś robisz z elementami
}
for (let i = 0; i < arr.length; i++) {
// znowu przechodzisz po tych samych danych
}W zapisie asymptotycznym O(n) + O(n) pozostaje O(n), bo stałe przestają mieć znaczenie. To jedna z tych rzeczy, które początkujący często widzą jako „podwójny koszt”, a w Big O po prostu upraszcza się do jednego rzędu wzrostu.
Zagnieżdżenie pętli podnosi koszt do O(n^2)
Jeśli każda iteracja zewnętrznej pętli uruchamia pełny przebieg pętli wewnętrznej, koszt rośnie kwadratowo:
for (let i = 0; i < n; i++) {
for (let j = 0; j < n; j++) {
// porównanie albo obliczenie
}
}Tu pierwszy poziom wykonuje się n razy, a drugi także n razy dla każdego z nich. W uproszczeniu dostajesz n * n, czyli O(n^2). Właśnie dlatego algorytmy z podwójną pętlą szybko zaczynają boleć przy większych danych.
Przeczytaj również: System dwójkowy dla programistów - Zrozum bity i bajty!
Dzielenie problemu na pół daje O(log n)
To drugi bardzo ważny wzorzec. Jeśli po każdym kroku odrzucasz połowę danych, liczba kroków rośnie bardzo wolno. Wyszukiwanie binarne jest tu najlepszym przykładem: zamiast sprawdzać wszystko po kolei, skaczesz do środka i zawężasz zakres.
W praktyce oznacza to, że przy milionie elementów nie wykonujesz miliona porównań, tylko około dwudziestu. Ten kontrast świetnie pokazuje, dlaczego logarytmiczna złożoność jest tak cenna w dużych zbiorach.
Sama liczba operacji to jednak tylko część historii. Czasem kod działa szybko, ale zużywa dużo pamięci. I właśnie tu zaczynają się kompromisy, o których początkujący często zapominają.
Czas działania to nie wszystko
Big O opisuje nie tylko czas, ale też złożoność pamięciową. To szczególnie ważne przy rekurencji, dużych tablicach tymczasowych i operacjach, które kopiują dane zamiast pracować „w miejscu”. W aplikacjach webowych to ma znaczenie szybciej, niż wiele osób przypuszcza, bo przeglądarka i środowisko uruchomieniowe też mają swoje limity.
Przykład praktyczny: algorytm może być szybki czasowo, ale tworzyć dużo dodatkowych struktur. Inny może być odrobinę wolniejszy, lecz oszczędniejszy w pamięci. W małych projektach różnica bywa niewidoczna, ale przy dużych zbiorach danych albo słabszych urządzeniach mobilnych już nie.
Warto też pamiętać o kompromisie między stabilnością a wydajnością. Jedne algorytmy, jak sortowanie przez scalanie, zwykle potrzebują dodatkowej pamięci, ale dają przewidywalne zachowanie. Inne, jak szybkie sortowanie, potrafią być bardzo szybkie w praktyce, lecz ich najgorszy przypadek wygląda mniej korzystnie. Big O pomaga takie wybory zobaczyć bez zgadywania.
Jest jeszcze jedna pułapka: algorytm z lepszą złożonością asymptotyczną nie zawsze wygrywa na małych danych. Narzut implementacji, wywołań funkcji czy kopiowania potrafi zjeść przewagę. Dlatego sama teoria nie wystarcza, jeśli nie umiesz jej czytać bez uproszczeń. A właśnie w uproszczeniach najłatwiej o błąd.
Najczęstsze błędy przy interpretacji zapisu
- Mylenie Big O z dokładnym czasem - zapis nie mówi, czy coś trwa 3 ms, czy 300 ms. Mówi, jak koszt rośnie wraz z danymi.
- Ignorowanie małych danych - algorytm o gorszym rzędzie może na małej próbce wyglądać podobnie albo nawet lepiej, bo ma mniejszy narzut.
- Zakładanie, że Big O zawsze oznacza najgorszy przypadek - w praktyce często tak się go upraszcza, ale sens notacji zależy od kontekstu analizy.
-
Przecenianie stałych -
O(2n)iO(n)to ten sam rząd wzrostu, choć w realnym kodzie konkretna implementacja nadal może mieć znaczenie. - Pomijanie pamięci - szybki algorytm, który tworzy dużo kopii, może okazać się gorszym wyborem niż trochę wolniejszy, ale lżejszy pamięciowo.
Ja traktuję Big O jak filtr decyzyjny, a nie wyrok. Pomaga odrzucić rozwiązania, które skaluą się źle, ale nie zastępuje pomiarów, profilu wydajności ani zdrowego rozsądku. Gdy ten filtr działa, łatwiej przejść od teorii do praktyki i sensownie dobierać rozwiązania w kodzie.
Jak wykorzystać tę wiedzę w nauce programowania
Najbardziej praktyczna część całej tematyki zaczyna się wtedy, gdy patrzysz na własny kod i pytasz: co stanie się, jeśli danych będzie dziesięć razy więcej? To pytanie bardzo szybko pokazuje, czy rozwiązanie jest tylko poprawne, czy także skalowalne.
W nauce programowania polecam prosty nawyk: przy każdej pętli policz, ile razy wykonuje się jej ciało, a przy każdej rekurencji sprawdź, czy problem jest dzielony, czy powielany. Jeśli rozwiązujesz zadanie na tablicach, zwracaj uwagę, czy szukasz elementu, filtrujesz dane, sortujesz je, czy może porównujesz każdą parę. Każdy z tych scenariuszy zwykle prowadzi do innej klasy złożoności.
W projektach webowych różnica szybko staje się widoczna. Kod, który działa płynnie dla kilkudziesięciu rekordów, może zacząć zamulać przy kilku tysiącach. Dlatego opłaca się wcześniej myśleć o strukturze danych i algorytmie, zamiast dopiero potem „ratować wydajność”. To jest właśnie moment, w którym Big O przestaje być teorią z wykładu, a staje się narzędziem projektowym.
Jeśli mam dać jedną radę na start, to taką: najpierw naucz się rozpoznawać wzorce złożoności, a dopiero potem wchodź w bardziej formalne definicje. Dzięki temu łatwiej czytać cudzy kod, rozmawiać o wydajności i podejmować rozsądne decyzje przy własnych rozwiązaniach. A gdy już to opanujesz, notacja przestaje być abstrakcją i zaczyna realnie pomagać w pisaniu lepszego kodu.
Co z tej notacji przydaje się najbardziej na start
Na początku nie trzeba znać całej matematycznej otoczki, żeby korzystać z Big O sensownie. Wystarczy rozumieć kilka podstawowych klas, umieć odróżnić pętlę liniową od zagnieżdżonej i pamiętać, że pamięć też ma swoją złożoność. To daje więcej praktycznej wartości niż mechaniczne zapamiętywanie definicji.
Jeśli miałbym zostawić tylko jedną myśl, byłaby prosta: Big O pomaga ocenić, czy rozwiązanie będzie rosło w sposób przewidywalny. Gdy widzisz O(n^2) przy dużych danych, zapala się czerwona lampka. Gdy widzisz O(log n) albo O(n log n), zwykle jesteś bliżej bezpiecznej strefy. I właśnie ta umiejętność odróżnia kod „działający” od kodu, który naprawdę nadaje się do większych zastosowań.