Algorytm to nie abstrakcyjny termin z podręcznika, tylko dokładny plan rozwiązania problemu. W praktyce pokazuję tu, jak rozpoznać dobry algorytm, jak przełożyć go na kod, jak ocenić jego szybkość i które błędy najczęściej blokują początkujących. To fundament, bez którego trudno pisać czytelny i stabilny kod, zwłaszcza w projektach webowych.
Najkrótsza wersja, zanim wejdziesz w szczegóły
- Algorytm to zestaw precyzyjnych kroków prowadzących od danych wejściowych do wyniku.
- Najpierw opisuję problem, a dopiero potem piszę kod, bo to oszczędza czas i zmniejsza liczbę błędów.
- W aplikacjach webowych często liczą się proste algorytmy: walidacja, filtrowanie, wyszukiwanie, sortowanie i paginacja.
- O jakości rozwiązania decyduje nie tylko poprawność, ale też złożoność czasowa i dobór struktury danych.
- Początkujący najczęściej przegrywają nie z teorią, tylko z pomijaniem przypadków brzegowych i testów.
Czym naprawdę jest algorytm w programowaniu
Gdy tłumaczę ten temat, zaczynam od prostego pytania: co ma wejść do programu, co ma z niego wyjść i w jakich krokach ma to się wydarzyć? Właśnie to jest algorytm. Nie musi być skomplikowany, ale musi być jednoznaczny. Jeśli komputer ma „domyślić się” brakującego kroku, to znaczy, że plan nie jest jeszcze gotowy.
W praktyce algorytm w programowaniu to plan działania zapisany tak, żeby dało się go wykonać bez zgadywania. Może dotyczyć bardzo prostych rzeczy, na przykład sprawdzenia, czy formularz ma poprawny adres e-mail, albo bardziej złożonych, jak sortowanie listy produktów po cenie. Najważniejsze jest to, że algorytm nie jest kodem samym w sobie, tylko logiką stojącą za kodem.
Warto też pamiętać, że większość algorytmów, z którymi zaczynasz, jest deterministyczna: te same dane wejściowe dają ten sam wynik. To daje przewidywalność, a ta w programowaniu jest bezcenna. Gdy to rozumiesz, łatwiej przejść od definicji do rozbijania problemu na kroki.
Jak rozbijam problem na kroki, które da się zakodować
Najczęstszy błąd widzę wtedy, gdy ktoś próbuje od razu pisać kod, chociaż jeszcze nie wie, co dokładnie ma się stać w środku pętli albo warunku. Ja robię odwrotnie: najpierw rozdzielam problem na małe części. Dzięki temu szybciej wychodzą błędy logiczne, zanim staną się błędami w edytorze.
- Określam dane wejściowe - sprawdzam, co program dostaje: tekst, liczbę, listę elementów, obiekt z formularza.
- Definiuję oczekiwany wynik - zapisuję, co ma wyjść: komunikat, posortowana lista, obliczona wartość, przekierowanie.
- Wyznaczam przypadki brzegowe - pusta lista, jeden element, duplikaty, błędny format, brak danych.
- Rozpisuję kroki pośrednie - dzielę problem na czynności, które komputer wykona po kolei.
- Testuję na małym przykładzie - przechodzę algorytm ręcznie, zanim zacznę go implementować.
To podejście jest szczególnie użyteczne w web developmentcie, bo tam bardzo często pracujesz z danymi, które mogą być niepełne albo niespójne. Jeśli już na etapie planu uwzględnisz wyjątki, kod później będzie prostszy. Zanim jednak kod powstanie, opłaca się zapisać plan w formie, którą da się sprawdzić.
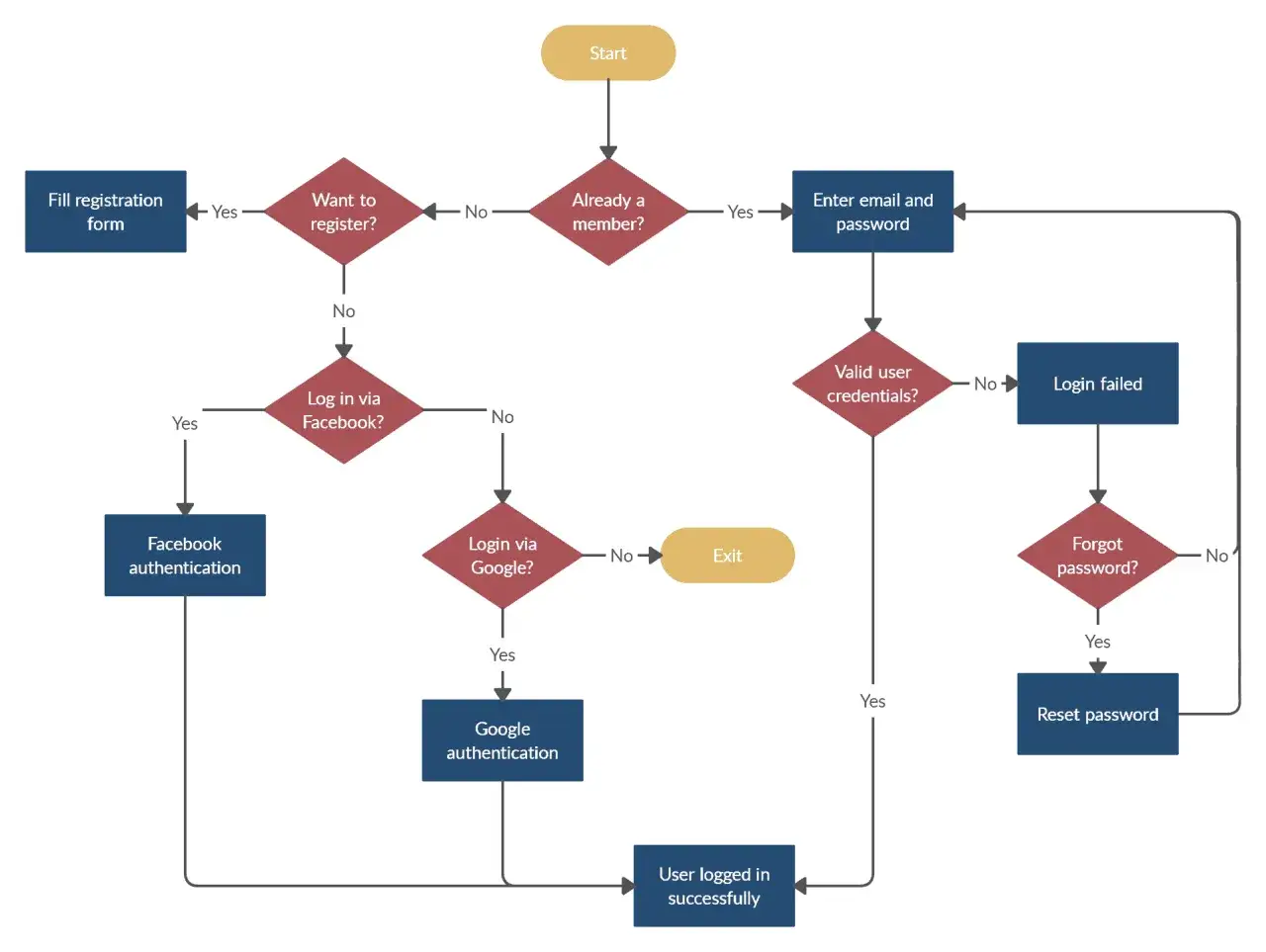
Jak zapisuję algorytm, zanim trafi do kodu
Na początku nauki nie potrzebujesz od razu rozbudowanego diagramu. W wielu przypadkach wystarczy pseudokod, czyli zapis przypominający język naturalny, ale ułożony tak, żeby nie gubić logiki. Ja traktuję go jak most między myśleniem a implementacją: jeszcze nie wiąże mnie składnia, ale już wymusza precyzję.
| Forma zapisu | Po co jej używam | Gdzie ma ograniczenia |
|---|---|---|
| Opis po ludzku | Pomaga szybko zrozumieć cel zadania i ustawić priorytety. | Bywa zbyt ogólny, jeśli trzeba sprawdzić każdy krok. |
| Pseudokod | Porządkuje logikę bez walki ze składnią języka. | Nie pokazuje wszystkich detali implementacyjnych. |
| Schemat blokowy | Dobry do warunków, pętli i rozgałęzień, bo wizualizuje przepływ. | Przy większych problemach szybko robi się nieczytelny. |
| Kod | Weryfikuje, czy pomysł da się faktycznie uruchomić. | Na zbyt wczesnym etapie potrafi ukryć błędy logiczne. |
Ja zazwyczaj zaczynam od pseudokodu, bo daje najlepszy stosunek prostoty do precyzji. Schemat blokowy jest świetny przy prostych rozgałęzieniach, ale nie warto go nadużywać. Taki zapis dobrze ujawnia błędy, zanim pojawią się w edytorze.
Algorytmy, które naprawdę pojawiają się w aplikacjach webowych
W webie rzadko pracujesz nad abstrakcyjnymi przykładami z podręcznika. Częściej chodzi o rzeczy bardzo konkretne: filtrowanie produktów, sortowanie tabeli, walidację formularza albo wyszukiwanie treści. I właśnie te zadania najlepiej pokazują, że algorytmika nie jest odległa od codziennego kodowania.
| Problem w aplikacji | Co robi algorytm | Na co uważać |
|---|---|---|
| Walidacja formularza | Sprawdza format e-maila, długość hasła i wymagane pola. | Walidacja po stronie klienta nie zastępuje walidacji po stronie serwera. |
| Filtrowanie listy produktów | Przechodzi po danych i zostawia tylko rekordy spełniające warunki. | Przy dużych zbiorach lepiej przenieść ciężką pracę na backend. |
| Sortowanie wyników | Układa elementy według ceny, daty lub popularności. | Zbyt częste sortowanie tej samej listy to łatwy sposób na spadek wydajności. |
| Wyszukiwanie po frazie | Odnajduje elementy pasujące do wpisanego tekstu. | Przy większych danych przydają się indeksy albo mechanizmy wyszukiwania po stronie serwera. |
| Paginacja | Dzieli dane na strony, żeby interfejs nie był przeładowany. | Trzeba pilnować spójności wyników, gdy użytkownik zmienia filtr. |
To są właśnie algorytmy, które spotykam najczęściej w praktyce. Nie wyglądają efektownie, ale robią ogromną różnicę w jakości produktu. Skoro wiesz już, jak działają najczęstsze wzorce, czas przyjrzeć się temu, co decyduje o ich szybkości.
Dlaczego złożoność czasowa ma znaczenie nawet w prostych projektach
Najkrócej: złożoność czasowa mówi, jak rośnie koszt obliczeń, gdy rośnie liczba danych. Nie chodzi o dokładne milisekundy, tylko o zachowanie algorytmu w większej skali. Na 20 elementach różnica bywa niewidoczna, ale przy 10 000 rekordów nagle okazuje się, że jedno rozwiązanie nadal działa płynnie, a drugie zaczyna przeszkadzać użytkownikowi.
| Złożoność | Intuicja | Przykład |
|---|---|---|
| O(1) | Stały koszt, niezależny od liczby danych. | Odczyt konkretnego elementu z tablicy po indeksie. |
| O(log n) | Problem jest dzielony na mniejsze części. | Wyszukiwanie binarne w posortowanej liście. |
| O(n) | Trzeba przejść po wszystkich elementach. | Filtrowanie listy lub policzenie wystąpień wartości. |
| O(n log n) | Dobry kompromis między prostotą a szybkością. | Wiele praktycznych algorytmów sortowania. |
| O(n²) | Koszt szybko rośnie przy zagnieżdżonych pętlach. | Porównywanie każdej pary elementów. |
Moja praktyczna zasada jest prosta: jeśli rozwiązanie działa na małej próbce, ale ma zagnieżdżone pętle bez wyraźnej potrzeby, zatrzymuję się i pytam, czy nie da się tego uprościć. O(n²) nie jest z definicji złe, ale w aplikacji webowej często bywa zbędnym obciążeniem. W praktyce to właśnie proste pomyłki najczęściej psują wynik, nie sama teoria.
Najczęstsze błędy, które psują nawet dobry pomysł
Największym problemem początkujących rzadko jest brak „talentu do algorytmów”. Zwykle chodzi o kilka powtarzalnych błędów, które pojawiają się wtedy, gdy człowiek za szybko przechodzi do implementacji albo testuje tylko jeden, wygodny przypadek.
- Zaczynanie od kodu - bez planu łatwo zgubić logikę i dopiero później próbować ją łatać.
- Pomijanie przypadków brzegowych - pusta lista, pojedynczy element albo duplikaty potrafią wywrócić nawet prosty algorytm.
- Mylenie walidacji z naprawianiem danych - sprawdzenie, czy dane są poprawne, to co innego niż próba ich „zgadnięcia”.
- Niepotrzebne zagnieżdżanie pętli - czasem problem da się rozwiązać jedną strukturą pomocniczą zamiast wielu przejść po tych samych danych.
- Testowanie tylko happy path - jeśli sprawdzasz wyłącznie poprawne dane, nie wiesz, jak program zachowa się w realnym użyciu.
Ja szczególnie pilnuję czterech testów: pustych danych, jednego elementu, duplikatów i danych niepoprawnych. To niewielki koszt, a bardzo często oszczędza późniejszego debugowania. Z takiego rytmu nauki najłatwiej przejść do bardziej złożonych zadań bez frustracji.
Jak ćwiczyć, żeby naprawdę zacząć myśleć algorytmicznie
Na początku nie trzeba robić setek zadań. Lepiej zrobić mniej, ale porządnie. Ja polecam krótką rutynę: 20-30 minut na jedno zadanie, z czego pierwsze 5 minut idzie na zrozumienie problemu, kolejne 10-15 minut na pseudokod, a reszta na implementację i testy. Taki rytm uczy dyscypliny myślenia, a nie tylko kopiowania składni.
- Weź jeden problem i opisz go jednym zdaniem.
- Zapisz dane wejściowe, wynik oraz 3 przypadki brzegowe.
- Rozpisz kroki w pseudokodzie, zanim zaczniesz pisać funkcję.
- Zaimplementuj rozwiązanie najprostszą możliwą drogą.
- Sprawdź je na 5 przykładach, w tym na danych błędnych.
Jeśli chcesz ćwiczyć pod web development, wybieraj zadania bliskie realnym projektom: walidację formularza, filtrowanie listy ofert, sortowanie komentarzy, liczenie statystyk albo deduplikację danych. Wtedy uczysz się nie tylko algorytmu, ale też myślenia o produkcie. To zwykle daje lepszy efekt niż abstrakcyjne łamigłówki, które nie mają żadnego kontekstu.
Jak utrwalić myślenie algorytmiczne bez chaosu
Na tym etapie najważniejsze jest nie to, żeby znać jak najwięcej nazw, tylko żeby umieć przejść od problemu do planu i od planu do kodu. Gdy to działa, reszta staje się dużo prostsza: rozumiesz, czemu jedno rozwiązanie jest szybsze, a inne bardziej czytelne, i potrafisz świadomie wybierać między nimi.
Jeśli miałbym zostawić jedną praktyczną wskazówkę, byłaby taka: zawsze najpierw zdefiniuj problem, potem jego przypadki graniczne, a dopiero na końcu wybieraj strukturę danych i pętle. Ten nawyk porządkuje naukę i bardzo dobrze przekłada się na pracę przy prawdziwych projektach. Gdy zaczynasz myśleć w ten sposób, algorytmy przestają być osobnym działem teorii, a stają się normalnym narzędziem codziennego programowania.