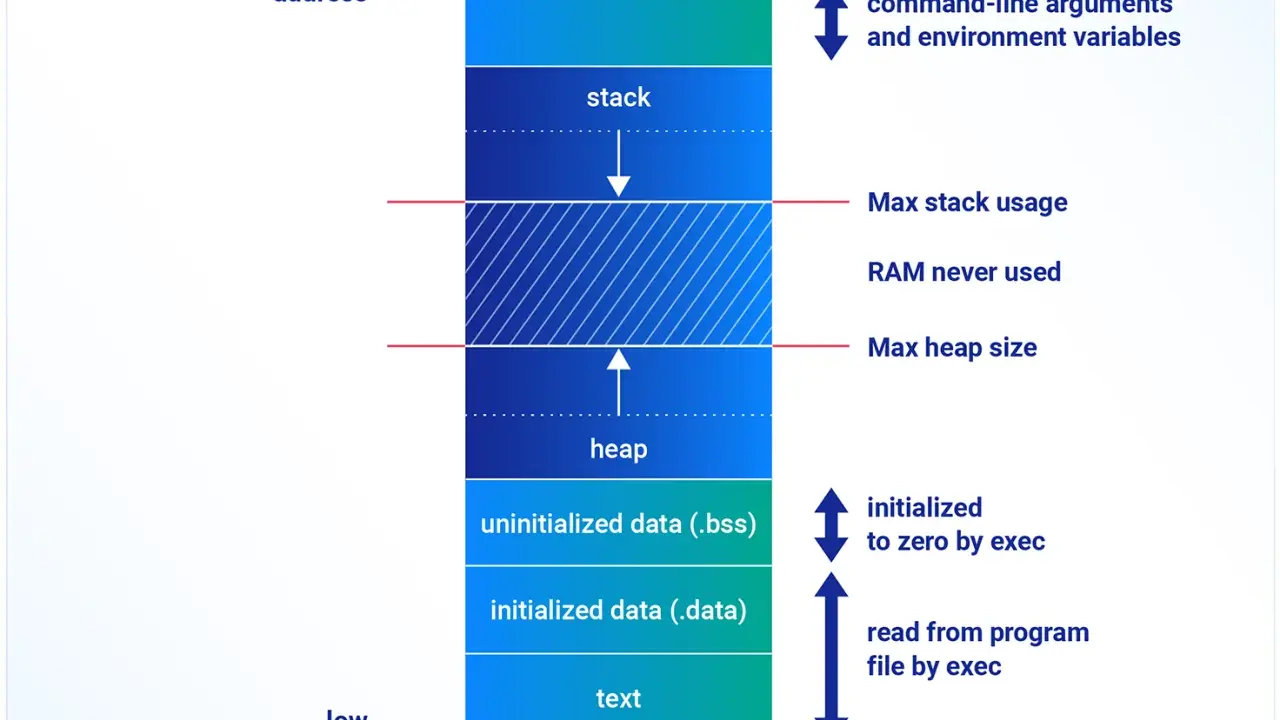
W projektach programistycznych pamięć potrafi być takim samym ograniczeniem jak czas wykonania. W tym tekście wyjaśniam, czym jest złożoność pamięciowa, jak odróżnić pamięć pomocniczą od samego wejścia i jak czytać kod pod kątem dodatkowych alokacji. Pokazuję też proste przykłady z tablic, rekurencji i struktur pomocniczych, bo właśnie tam początkujący najczęściej tracą kontrolę nad zużyciem RAM.
Najkrócej chodzi o dodatkową pamięć, nie o sam rozmiar danych
- To miara tego, ile dodatkowej pamięci potrzebuje algorytm, aby wykonać zadanie.
- Najczęściej patrzy się na pamięć pomocniczą, czyli tablice robocze, kopie danych i stos wywołań.
- O(1) oznacza stały koszt pamięci, a O(n) wzrost proporcjonalny do rozmiaru danych.
- Ta sama funkcja może być oszczędna czasowo, ale kosztowna pamięciowo, albo odwrotnie.
- W praktyce największe różnice robią kopie kolekcji, rekurencja i struktury pomocnicze tworzone w pętli.
Co naprawdę mierzy zużycie pamięci algorytmu
Najprościej patrzę na to tak: algorytm ma pewien budżet pamięci, który konsumuje podczas działania. Część tej pamięci to dane wejściowe, a część to wszystko, co trzeba utworzyć po drodze, żeby dojść do wyniku. W praktyce właśnie ta druga część interesuje nas najbardziej, bo to ona rośnie wraz z decyzjami projektowymi i potrafi zaskoczyć przy większym wejściu.
W książkach i materiałach edukacyjnych definicje bywają trochę różne, ale sens zostaje ten sam: chodzi o to, jak pamięć zmienia się wraz z rozmiarem danych. Jeśli algorytm pracuje na kilku licznikach i niczego nie kopiuje, zwykle mieści się w stałym koszcie pamięci. Jeśli tworzy dodatkową tablicę, stos pomocniczy albo cały zbiór pośredni, koszt zaczyna rosnąć wraz z n. To jest dobry moment, żeby odróżnić pamięć potrzebną do przechowywania danych od pamięci dodatkowej, bo to rozróżnienie wraca potem niemal w każdym porównaniu algorytmów.
W praktyce uczę się oceniać kod przez odpowiedź na jedno pytanie: czy algorytm może działać na tym, co już ma, czy musi zbudować coś nowego? Od tej odpowiedzi zwykle zaczyna się sensowna analiza, a dalej naturalnie przechodzi się do porównania z czasem działania.
Jak ta miara ma się do czasu działania
Najczęstszy błąd początkujących polega na zakładaniu, że wydajność to tylko szybkość. W rzeczywistości dwa algorytmy mogą zwracać ten sam wynik, ale jeden zużyje dużo RAM-u, a drugi prawie nic. Czas i pamięć są powiązane, lecz nie są tym samym, dlatego często trzeba wybierać między jednym a drugim.
| Cecha | Czas działania | Pamięć |
|---|---|---|
| Co mierzy | Liczbę operacji i tempo wykonania | Ilość dodatkowej przestrzeni użytej podczas pracy |
| Typowy problem | Program działa zbyt wolno | Program przekracza limit pamięci albo zaczyna zwalniać |
| Typowy kompromis | Więcej obliczeń, mniej struktur pomocniczych | Więcej buforów i kopii, mniej powtórnych obliczeń |
| Co bywa mylące | Biblioteczna funkcja wygląda na prostą, ale ukrywa kosztowne przetwarzanie | Rekurencja nie tworzy jawnej tablicy, ale nadal zajmuje stos wywołań |
Ja zwykle patrzę na ten kompromis bardzo pragmatycznie: jeśli rozwiązanie ma działać na małych danych, priorytetem bywa prostota. Jeśli ma obsłużyć setki tysięcy albo miliony elementów, zaczyna się liczyć każdy dodatkowy bufor. To prowadzi wprost do przykładów, które najlepiej pokazują, skąd bierze się koszt pamięciowy w kodzie.
Jak to wygląda na tablicach, rekurencji i strukturach pomocniczych
Najłatwiej zrozumieć temat na przykładach z codziennego kodu. W JavaScript i innych językach webowych bardzo często problemem nie jest sam algorytm jako pomysł, tylko to, że po drodze tworzy on nowe kolekcje. Z pozoru niewinna operacja na tablicy może w praktyce oznaczać dodatkową kopię całej struktury.
| Przykład | Typowy koszt pamięciowy | Dlaczego tak się dzieje |
|---|---|---|
| Sumowanie elementów w jednej pętli | O(1) | Potrzebujesz tylko kilku zmiennych roboczych, bez nowych kolekcji |
map lub filter na dużej tablicy |
O(n) | Powstaje nowa tablica wynikowa, której rozmiar rośnie wraz z wejściem |
| Rekurencyjne przejście po drzewie | O(h) | Zajętość zależy od głębokości wywołań, a nie tylko od liczby węzłów |
| Sortowanie z dodatkowym buforem pomocniczym | O(n) | Algorytm potrzebuje przestrzeni do scalania albo tymczasowych kopii |
| Odwrócenie tablicy przez zamianę elementów w miejscu | O(1) | Nie tworzysz drugiej tablicy, tylko podmieniasz wartości |
Zwracam uwagę na rekurencję, bo ona często myli najbardziej. Nie widać tam jawnej tablicy ani bufora, więc łatwo uznać kod za „lekki”. Tymczasem każdy poziom wywołania zajmuje miejsce na stosie i przy zbyt dużej głębokości potrafi wyczerpać pamięć szybciej, niż się spodziewasz. Skoro to już widać w przykładach, warto przejść do prostego schematu oceny własnego kodu.
Jak oceniam kod bez zgadywania
Jeżeli mam szybko oszacować koszt pamięciowy, idę zawsze tą samą ścieżką. To nie jest skomplikowane, ale wymaga dyscypliny, bo łatwo pominąć jeden detal i całkiem zmienić wynik analizy.
- Sprawdzam, czy algorytm tworzy nowe kolekcje proporcjonalne do rozmiaru wejścia.
- Liczę wszystkie buforowania, kopie, tablice pomocnicze i mapy tworzone w trakcie działania.
- Jeśli jest rekurencja, oceniam głębokość stosu zamiast patrzeć tylko na liczbę danych.
- Oddzielam pamięć stałą od tej, która rośnie wraz z n lub z głębokością drzewa.
- Nie ufam intuicji wobec funkcji bibliotecznych, dopóki nie wiem, czy działają w miejscu, czy budują nowy wynik.
W praktyce najważniejsze pytanie brzmi: czy koszt jest stały, liniowy, czy może zależy od głębokości przetwarzania? To właśnie ten szczegół decyduje, czy rozwiązanie da się bezpiecznie uruchomić na większym zbiorze danych. Gdy już umiesz to sprawdzać, pozostaje najciekawsza część: jak ograniczać zużycie pamięci, nie psując czytelności kodu.
Jak ograniczać pamięć bez psucia rozwiązania
Nie każda optymalizacja ma sens, ale kilka zasad działa niemal zawsze. Ja zaczynam od najprostszych rzeczy, bo one zwykle dają największy efekt przy najmniejszym koszcie utrzymania kodu.
- Przetwarzaj dane strumieniowo, jeśli nie potrzebujesz całego wyniku naraz.
- Unikaj niepotrzebnych kopii tablic i obiektów, zwłaszcza w pętlach.
- Wybieraj iterację zamiast głębokiej rekurencji, jeśli istnieje ryzyko dużego stosu wywołań.
- Używaj struktur takich jak
SetczyMapwtedy, gdy oszczędność czasu naprawdę uzasadnia koszt pamięci. - Usuwaj dane tymczasowe jak najwcześniej, zamiast trzymać je do końca funkcji bez potrzeby.
Tu jednak wchodzi ważny kompromis: nie zawsze warto gonić za minimalnym zużyciem pamięci kosztem prostoty. Przy małych danych różnica może być praktycznie niewidoczna, a czytelność będzie miała większą wartość niż mikrooptymalizacja. Inaczej wygląda to przy dużych zbiorach, w aplikacjach mobilnych, w przeglądarce albo w funkcjach serverless, gdzie limit pamięci bywa bardzo konkretny. To właśnie ten kontekst decyduje, czy poprawka ma sens, czy jest tylko sztuką dla sztuki.
Co warto zapamiętać przy pisaniu własnych algorytmów
Jeśli miałbym zostawić jedną praktyczną regułę, brzmiałaby tak: zanim uznasz kod za dobry, sprawdź, czy nie ukrywa kosztownej kopii danych albo zbyt głębokiego stosu wywołań. Te dwa miejsca najczęściej podnoszą koszt pamięci bardziej niż sama logika problemu.
- Najpierw myśl o danych, które trzymasz w pamięci, a dopiero potem o samych obliczeniach.
- Porównuj rozwiązania nie tylko pod kątem szybkości, ale też dodatkowej przestrzeni.
- Patrz na najgorszy przypadek, jeśli kod ma działać na dużych lub nieprzewidywalnych wejściach.
- Nie zakładaj, że „mała” funkcja biblioteczna jest automatycznie tania pamięciowo.
Dla osoby uczącej się programowania najlepszy nawyk jest prosty: przy każdym zadaniu pytaj nie tylko, ile operacji wykona algorytm, ale też ile dodatkowej przestrzeni potrzebuje w najgorszym przypadku. Taki sposób myślenia szybko porządkuje kod i pomaga pisać rozwiązania, które nie rozsypią się przy większym wejściu.