Najważniejsze wnioski o sortowaniu w jednym miejscu
- W sortowaniu porównawczym dolna granica to zwykle Ω(n log n), więc nie da się jej przeskoczyć samymi porównaniami.
- Merge sort daje stabilne O(n log n), ale wymaga dodatkowej pamięci.
- Quicksort jest szybki w praktyce, lecz ma pesymistyczny przypadek O(n^2) i zależy od wyboru pivota.
- Heapsort ma pewne O(n log n) i mały narzut pamięci, ale nie jest stabilny.
- Dla małego zakresu liczb opłaca się wyjść poza model porównań i użyć counting sort albo radix sort.
- Przy wyborze algorytmu liczą się nie tylko czasy, ale też stabilność, pamięć i charakter danych.
Jak czytać złożoność sortowania bez pułapek
Patrzę na sortowanie w trzech wymiarach: czasu, pamięci i zachowania na danych równych lub prawie uporządkowanych. Sama notacja O(...) mówi tylko o tempie wzrostu kosztu, a nie o tym, czy algorytm jest stabilny, czy działa in-place, ani czy radzi sobie lepiej, gdy wejście jest już częściowo ułożone.- O(...) opisuje górne ograniczenie wzrostu, czyli to, jak koszt zachowa się dla dużych danych.
- Ω(...) pokazuje dolne ograniczenie, czyli czego nie da się przebić w danym modelu.
- Θ(...) oznacza, że górna i dolna granica są tego samego rzędu.
- Stabilność mówi, czy równoważne elementy zachowują swoją kolejność.
- In-place znaczy, że algorytm używa bardzo mało dodatkowej pamięci.
W praktyce te cechy bywają ważniejsze niż sama „ładna” asymptotyka. Dla listy zamówień, produktów albo rekordów użytkowników stabilność potrafi zdecydować o tym, czy kolejne sortowanie nie zniszczy poprzedniego porządku. To prowadzi do pytania, skąd bierze się teoretyczna granica dla klasycznych sortowań.
Skąd bierze się granica n log n w sortowaniu porównawczym
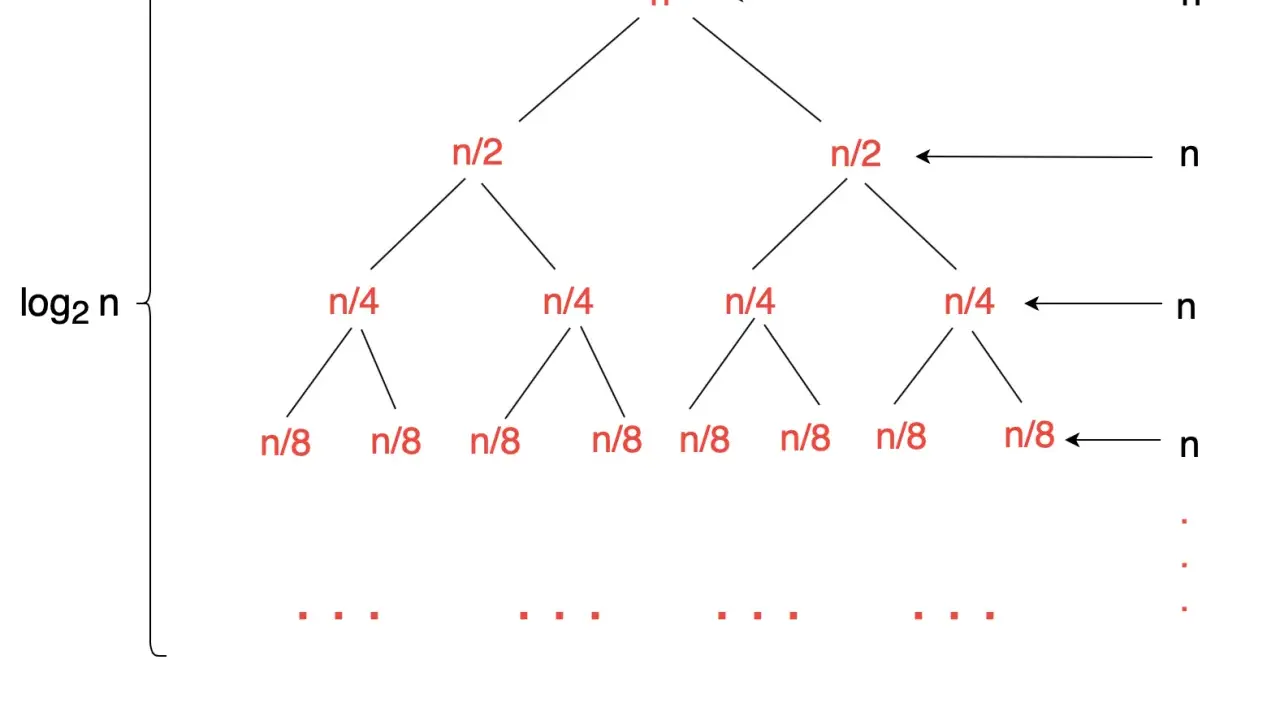
W sortowaniu opartym wyłącznie na porównaniach algorytm może zdobywać informację tylko przez odpowiedzi „tak” lub „nie”. To oznacza, że dla n różnych elementów musi rozróżnić n! możliwych permutacji, a każda dodatkowa decyzja tylko rozgałęzia przestrzeń wyników. Z tego powodu minimalna wysokość drzewa decyzyjnego rośnie jak log(n!), czyli asymptotycznie jak n log n.
To nie jest akademicka ciekawostka. Jeśli porównujesz liczby, daty, napisy albo obiekty według własnego komparatora, to właśnie w tym modelu żyje większość popularnych algorytmów: insertion sort, merge sort, quicksort i heapsort. Dlatego nie spodziewam się, że któryś z nich magicznie przebije barierę o cały rząd wielkości, chyba że przestanie bazować wyłącznie na porównaniach.W praktyce oznacza to też coś odwrotnego: jeśli dane mają dodatkową strukturę, można zejść niżej. Gdy sortujesz niewielki zakres liczb całkowitych albo klucze o stałej długości, counting sort i radix sort korzystają z tych własności zamiast z samego porównywania elementów. To właśnie dlatego warto porównać najpopularniejsze metody obok siebie, a nie wrzucać wszystkich do jednego worka.
Jak wypadają najważniejsze algorytmy sortowania
Jeśli mam szybko uporządkować wybór, to zaczynam od takiej tabeli. Pokazuje ona nie tylko czas działania, ale też koszt pamięci i to, czy algorytm nadaje się do rekordów, które mają zachować swoją kolejność.| Algorytm | Czas | Pamięć | Stabilność | Kiedy ma sens |
|---|---|---|---|---|
| Insertion sort | O(n) / O(n^2) / O(n^2) | O(1) | Tak | Małe lub prawie posortowane dane |
| Selection sort | O(n^2) / O(n^2) / O(n^2) | O(1) | Nie | Gdy liczy się mało zamian, a nie czas |
| Merge sort | O(n log n) / O(n log n) / O(n log n) | O(n) | Tak | Duże dane, sortowanie stabilne, zbiory zewnętrzne |
| Quicksort | Średnio O(n log n), pesymistycznie O(n^2) | Zwykle O(log n), pesymistycznie O(n) | Nie | Gdy ważna jest szybkość przeciętna |
| Heapsort | O(n log n) / O(n log n) / O(n log n) | O(1) | Nie | Gdy chcesz gwarancji i małej pamięci |
| Counting sort | O(n + k) | O(n + k) | Tak | Liczby całkowite o małym zakresie |
| Radix sort | O(d(n + k)) | O(n + k) | Tak, jeśli kroki pomocnicze są stabilne | Stała liczba cyfr, znaków albo pól |
Najważniejsze rozróżnienie jest takie: merge, quick, heap, insertion i selection to sortowania porównawcze, więc ich asymptotyka mieści się w ramach modelu z ograniczeniem n log n. Counting i radix korzystają z własności danych, więc mogą zejść niżej, ale tylko wtedy, gdy zakres wartości i format klucza na to pozwalają. To jest miejsce, w którym teoria zaczyna naprawdę pomagać w wyborze narzędzia.
Który algorytm wybrać w realnym projekcie
W kodzie produkcyjnym nie wybieram sortowania wyłącznie po samym czasie asymptotycznym. Patrzę na to, czy dane są małe, czy wynik ma być stabilny, ile pamięci mogę zużyć i czy wartości da się opisać prostym zakresem albo liczbą cyfr. To daje prosty podział, który działa lepiej niż ogólne slogany.
- Małe lub prawie posortowane tablice - insertion sort często wygrywa, bo ma niski narzut i dobrze reaguje na lokalny porządek.
- Duże zbiory, gdzie liczy się stabilność - merge sort jest bezpiecznym wyborem, zwłaszcza gdy później sortujesz po kilku polach.
- Ograniczona pamięć - heapsort daje pewne O(n log n) i nie wymaga dużej przestrzeni pomocniczej.
- Najważniejsza jest szybkość przeciętna - quicksort lub hybryda oparta na quicksortcie zwykle sprawdza się bardzo dobrze, ale trzeba uważać na dobór pivota.
- Liczby całkowite w małym zakresie - counting sort potrafi być prostszy i szybszy od każdego sortowania porównawczego.
- Stała liczba cyfr, znaków lub pól - radix sort bywa bardzo efektywny, bo porządkuje dane etapami zamiast porównywać każdą parę elementów.
W aplikacjach webowych szczególnie często trafiam na sytuację, w której stabilność ma znaczenie większe, niż wygląda na pierwszy rzut oka. Jeśli sortujesz listę użytkowników najpierw po statusie, a potem po dacie, zachowanie kolejności przy równych wartościach może oszczędzić ci dodatkowych błędów logicznych. To naturalnie prowadzi do pytań o typowe pomyłki przy liczeniu złożoności.
Najczęstsze błędy przy ocenianiu sortowania
Najbardziej typowy błąd to mylenie teorii z pomiarem na małym zbiorze danych. Algorytm o gorszej asymptotyce potrafi wygrać na krótkiej liście, bo ma mniejszy narzut, mniej alokacji albo lepiej pasuje do pamięci podręcznej procesora.
- Patrzenie tylko na best case - quicksort z dobrym pivotem wygląda świetnie, ale pesymistyczny przypadek nadal istnieje.
- Ignorowanie stabilności - przy danych z wieloma polami niestabilny sort potrafi zepsuć wcześniejszy porządek.
- Mieszanie modeli - comparison sort i counting sort nie są uczciwie porównywalne bez zrozumienia założeń o danych.
- Pomijanie pamięci dodatkowej - merge sort bywa świetny, ale jego koszt przestrzenny nie jest zerowy.
- Przecenianie mikrozysków - jeśli sortowanie nie jest wąskim gardłem, lepiej poprawić model danych albo ograniczyć liczbę porównań.
Ja zwykle zaczynam od pytania: czy ten algorytm ma być przewidywalny, czy tylko szybki średnio? Dopiero potem schodzę do detali implementacyjnych. Dzięki temu łatwiej uniknąć sytuacji, w której ładna teoria przegrywa z realnym użyciem. Właśnie dlatego na końcu warto spiąć wszystko jedną praktyczną zasadą.
Co warto zapamiętać, gdy sortowanie trafia do kodu produkcyjnego
Najkrótszy skrót, który sam trzymam w głowie, jest taki: sortowania porównawcze mają sufit na poziomie n log n, ale to nie znaczy, że każdy algorytm w tej klasie zachowuje się podobnie. Merge sort daje stabilność i przewidywalność, quicksort zwykle wygrywa przeciętną szybkością, heapsort chroni pamięć, a counting i radix sort robią krok w bok od klasycznego modelu, gdy dane na to pozwalają.
Jeśli mam zostawić jedną praktyczną wskazówkę, to brzmi ona tak: najpierw dopasuj algorytm do typu danych i ograniczeń projektu, a dopiero potem optymalizuj implementację. Przy dobrze dobranym sortowaniu zyskujesz więcej niż na kolejnych drobnych poprawkach w pętli. Właśnie w tym miejscu teoria przestaje być sucha i zaczyna realnie pomagać w programowaniu.