Wzorzec publisher subscriber, czyli publish/subscribe, porządkuje komunikację tam, gdzie jedna część systemu wysyła zdarzenie, a wiele innych może na nie zareagować bez bezpośredniego wskazywania odbiorców. W praktyce oznacza to mniej zależności między modułami, lepsze skalowanie i prostsze dokładanie nowych funkcji bez rozbierania całej architektury. Poniżej wyjaśniam, jak ten model działa, kiedy faktycznie się opłaca, czym różni się od kolejki i obserwatora oraz jakie błędy najczęściej psują wdrożenie.
Najważniejsze informacje o komunikacji pub/sub
- Nadawca publikuje wiadomość do tematu, a nie do konkretnego odbiorcy.
- Subskrybenci zapisują się do interesujących ich tematów lub filtrów.
- Ten model dobrze sprawdza się przy zdarzeniach, powiadomieniach i integracji usług.
- Nie każda implementacja gwarantuje trwałość, kolejność i brak duplikatów.
- Największe ryzyka to zbyt szerokie tematy, brak wersjonowania danych i słaby monitoring.
- W prostych zadaniach kolejka lub zwykły observer bywają lepszym wyborem.
Czym jest wzorzec komunikacji pub/sub w praktyce
Ja traktuję ten model jako sposób na oddzielenie pytania „co się stało?” od pytania „kto ma to odebrać?”. Publisher nie zna odbiorców, a subscriber nie musi wiedzieć, kto wygenerował zdarzenie. To właśnie dlatego ten wzorzec tak dobrze pasuje do systemów event-driven, w których różne części aplikacji reagują na te same fakty biznesowe, ale robią z nimi coś zupełnie innego.
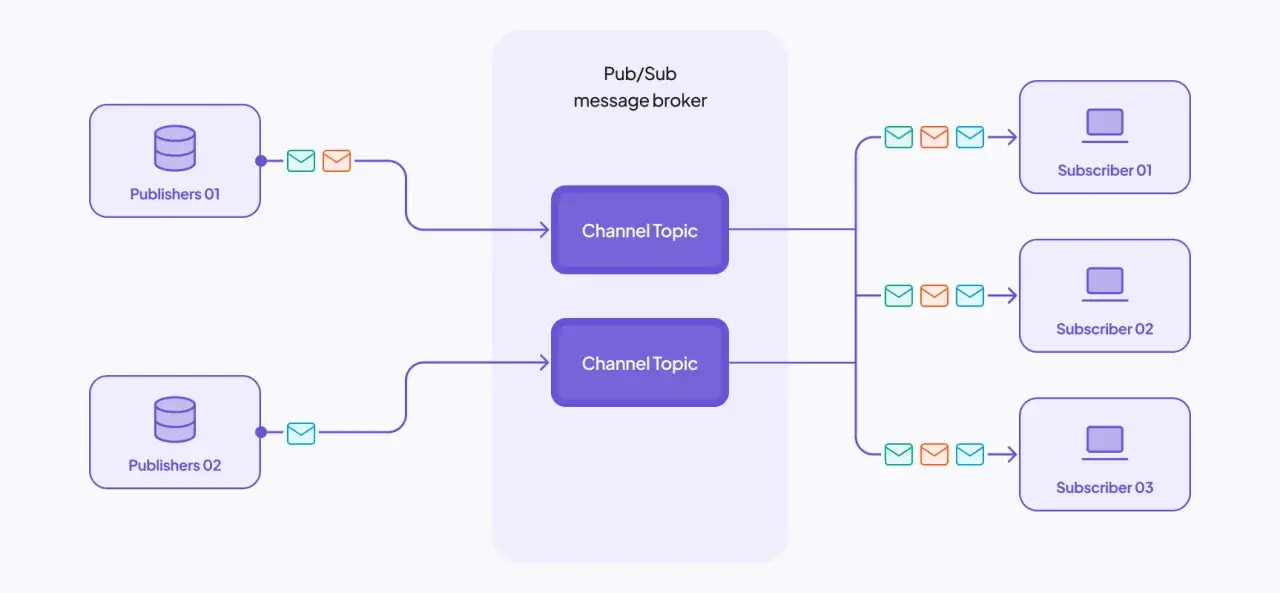
W praktyce pośrodku zwykle stoi broker, event bus albo temat, czyli warstwa pośrednia, która przyjmuje wiadomość i rozsyła ją dalej do zainteresowanych stron. Taki układ pozwala dodać nowego odbiorcę bez zmiany kodu nadawcy, a to w architekturze webowej daje realną swobodę rozwoju. Żeby jednak dobrze z niego korzystać, trzeba najpierw zobaczyć, jak dokładnie przepływa pojedyncza wiadomość.
Jak działa przepływ wiadomości między nadawcą a odbiorcami
Typowy przebieg jest prosty, ale za tą prostotą kryją się ważne decyzje projektowe. Publisher tworzy wiadomość, broker przyjmuje ją i na podstawie tematu albo reguł filtrowania przekazuje do wszystkich pasujących subskrybentów. Każdy subscriber dostaje własną kopię zdarzenia, więc ten sam komunikat może uruchomić kilka niezależnych procesów jednocześnie.
- Publikacja - nadawca wysyła zdarzenie, na przykład „zamówienie opłacone” albo „użytkownik zmienił hasło”.
- Dystrybucja - pośrednik rozpoznaje temat wiadomości i decyduje, komu ją dostarczyć.
- Subskrypcja - odbiorca zapisuje się na interesujący go temat lub zestaw warunków.
- Przetwarzanie - konsument wykonuje swoją pracę niezależnie od innych odbiorców.
- Potwierdzenie lub retry - w niektórych systemach wiadomość jest potwierdzana, ponawiana albo trafia do kolejki martwych wiadomości.
Warto rozróżnić dwa popularne sposoby filtrowania. Przy filtrowaniu tematycznym subskrybent zapisuje się do konkretnego kanału, więc dostaje wszystko, co tam trafia. Przy filtrowaniu po treści odbiorca definiuje warunek oparty na danych wiadomości, co daje większą precyzję, ale zwykle komplikuje konfigurację i debugging. To prowadzi do ważnego pytania: gdzie taki model naprawdę daje przewagę, a gdzie tylko dodaje warstwę złożoności.
Gdzie ten model naprawdę pomaga w aplikacjach webowych
W projektach webowych widzę ten wzorzec najczęściej tam, gdzie jedno zdarzenie musi uruchomić kilka niezależnych reakcji. Zamiast wywoływać kolejne serwisy jeden po drugim, publikujesz fakt i pozwalasz reszcie systemu samodzielnie zareagować. To brzmi prosto, ale działa dobrze tylko wtedy, gdy faktycznie potrzebujesz luźnego powiązania między komponentami.
- Powiadomienia użytkownika - po utworzeniu zamówienia jeden subscriber może wysłać e-mail, inny powiadomienie push, a jeszcze inny zaktualizować panel administracyjny.
- Integracje mikroserwisów - jeden serwis publikuje zdarzenie domenowe, a kilka innych aktualizuje własne widoki danych bez bezpośrednich wywołań HTTP.
- Analityka i telemetria - aplikacja publikuje zdarzenia o zachowaniach użytkownika, a osobne procesy budują raporty, metryki lub alerty.
- Odświeżanie cache i indeksów - zmiana w bazie może uruchomić odświeżenie cache, reindeksację wyszukiwarki i synchronizację z zewnętrznym systemem.
- Interfejsy real-time - dashboardy, czaty i panele monitorujące zyskują na modelu, w którym nowe dane są rozsyłane do zainteresowanych klientów natychmiast po publikacji.
Nie wybrałbym tego wzorca jako pierwszego wyboru do procesu, w którym jedna operacja musi zakończyć się dokładnie raz, w ściśle określonej kolejności i z natychmiastowym potwierdzeniem. W takich przypadkach prostsza kolejka albo jawny workflow często daje większą kontrolę. I właśnie dlatego warto odróżnić pub/sub od podobnych pojęć, które na papierze wyglądają podobnie, ale w praktyce rozwiązują inne problemy.
Czym pub/sub różni się od kolejki i obserwatora
W rozmowach technicznych te trzy pojęcia są często wrzucane do jednego worka, a to później kończy się błędnymi decyzjami architektonicznymi. Kolejka, pub/sub i observer mają wspólny motyw komunikacji zdarzeń, ale różnią się semantyką dostarczania, zakresem działania i typowym zastosowaniem. Najłatwiej widać to w bezpośrednim porównaniu.
| Kryterium | Pub/sub | Kolejka | Observer |
|---|---|---|---|
| Liczba odbiorców | Jeden komunikat trafia do wielu subskrybentów | Zwykle jeden komunikat obsługuje jeden konsument | Wiele obserwatorów reaguje na zmianę stanu jednego obiektu |
| Sprzężenie | Niskie, nadawca nie zna odbiorców | Niskie, ale semantyka jest bardziej zadaniowa niż zdarzeniowa | Średnie, bo komponenty zwykle działają w tym samym procesie |
| Zakres użycia | Systemy rozproszone, eventy domenowe, integracje | Przetwarzanie zadań, worker pool, job queue | UI, model danych, lokalne reakcje w jednej aplikacji |
| Największa zaleta | Rozsyłanie jednej informacji do wielu zainteresowanych stron | Kontrola nad wykonaniem pojedynczego zadania | Prosta reakcja na zmianę bez rozbudowanej infrastruktury |
| Największe ryzyko | Duplikaty, utrata wiadomości, trudniejszy debugging | Kolejki blokują się przy wolnych workerach | Łatwo przechodzi w ciasne powiązanie klas |
Jeśli potrzebujesz, by to samo zdarzenie uruchomiło kilka niezależnych reakcji, pub/sub jest naturalnym wyborem. Jeśli chcesz, by jedno zadanie zostało wykonane raz przez jeden worker, lepiej sprawdzi się kolejka. Gdy reagujesz lokalnie na zmianę stanu obiektu w jednym procesie, observer bywa prostszy i mniej kosztowny. Właśnie na tym etapie wiele wdrożeń zaczyna się komplikować niepotrzebnie, bo wzorzec jest dobierany do nazwy technologii, a nie do problemu.
Najczęstsze błędy przy wdrażaniu komunikacji eventowej
Najwięcej problemów nie bierze się z samego wzorca, tylko z założeń, które są z nim sprzeczne. Widziałem projekty, w których pub/sub miał „uprościć architekturę”, a w praktyce ukrył zależności w wiadomościach, których nikt nie dokumentował. To się mści po kilku miesiącach, kiedy liczba konsumentów rośnie, a nikt nie wie już, kto i dlaczego reaguje na dany event.
- Zbyt szerokie tematy - jeden kanał typu „system-events” szybko staje się śmietnikiem, w którym mieszają się zdarzenia o zupełnie różnym znaczeniu.
- Brak wersjonowania wiadomości - gdy payload się zmienia, starsi konsumenci przestają rozumieć nowe pola albo interpretują je błędnie.
- Brak idempotencji - subscriber powinien bezpiecznie poradzić sobie z ponownym dostarczeniem tego samego zdarzenia, bo duplikaty są w wielu systemach normalne.
- Za duży payload - jeśli w wiadomości upychasz pół encji z bazy, każdy konsument dostaje więcej danych, niż naprawdę potrzebuje, a kontrakt staje się kruchy.
- Brak obserwowalności - bez logów, metryk i śledzenia opóźnień trudno zauważyć, że wiadomości stoją w kolejce albo giną po drodze.
- Próba zbudowania logiki krytycznej na best-effort - jeśli dane zdarzenie musi być obsłużone niezawodnie, trzeba świadomie zaprojektować retry, potwierdzenia i mechanizmy awaryjne.
Najprostsza zasada, którą sam stosuję, brzmi tak: jeśli nie umiesz opisać wiadomości jednym zdaniem biznesowym, to prawdopodobnie temat jest źle zdefiniowany. A skoro wiadomo już, co najczęściej psuje wdrożenie, zostaje ostatnia rzecz: co ustalić zanim taki model trafi na produkcję.
Co warto ustalić przed pierwszym wdrożeniem
Gdy projektuję taki układ, zawsze zaczynam od kilku twardych decyzji, a dopiero później wybieram narzędzie. To oszczędza czas, bo technologia staje się odpowiedzią na konkretne wymagania, a nie odwrotnie. Jeśli te punkty są jasne od początku, komunikacja eventowa naprawdę pomaga porządkować system zamiast go zaciemniać.
- Określ, kto jest właścicielem zdarzenia i kto odpowiada za jego schemat.
- Ustal, czy wiadomości mają być trwałe, czy mogą zniknąć po dostarczeniu.
- Zdefiniuj zasady retry, timeoutów i kolejek martwych wiadomości.
- Zadbaj o idempotencję konsumentów, żeby ponowne dostarczenie nie psuło danych.
- Wprowadź wersjonowanie payloadu, nawet jeśli na początku wydaje się zbędne.
- Dodaj metryki opóźnienia, liczby błędów i czasu przetwarzania, bo bez tego nie zobaczysz, że system zaczyna się dławić.
Jeśli potraktujesz pub/sub jako świadomy kontrakt między częściami systemu, a nie jako modny skrót do „luźno połączonych serwisów”, dostaniesz architekturę, którą da się rozwijać bez ciągłego przepisywania wszystkiego od zera. Właśnie dlatego ten wzorzec jest tak ważny w nowoczesnych aplikacjach webowych: dobrze użyty upraszcza życie zespołu, źle użyty tylko przenosi chaos w inne miejsce.