W programowaniu metoda naiwna bywa najlepszym sposobem na start: pozwala szybko zrozumieć problem, sprawdzić poprawność i zobaczyć, gdzie naprawdę leży trudność. To zwykle najprostszy algorytm, który nie próbuje być sprytny, tylko przechodzi przez wszystkie oczywiste możliwości. W tym tekście wyjaśniam, czym takie podejście jest w praktyce, pokazuję proste przykłady i tłumaczę, kiedy przestaje wystarczać.
Najpierw proste rozwiązanie, potem dopracowanie
- Naiwny algorytm to najprostsza wersja rozwiązania, bez optymalizacji i skrótów.
- W podstawach programowania pomaga zrozumieć problem i szybko napisać działający kod.
- Najlepiej sprawdza się przy małych danych, prototypach i zadaniach edukacyjnych.
- Największy problem pojawia się wtedy, gdy liczba operacji rośnie szybciej niż rozmiar danych.
- Dobry nawyk to najpierw napisać wersję prostą, a dopiero potem poprawiać wydajność.
Co oznacza naiwny algorytm w programowaniu
W programowaniu naiwny algorytm to po prostu najprostszy poprawny sposób rozwiązania zadania. Zwykle polega na sprawdzeniu wszystkich możliwości albo na bezpośrednim przejściu po danych krok po kroku, bez kombinowania z dodatkowymi strukturami, heurystykami czy sprytnymi skrótami. To nie jest obraźliwe określenie. W praktyce chodzi o rozwiązanie, które jest łatwe do zrozumienia, łatwe do zapisania i często bardzo dobre jako pierwszy szkic.
Takie podejście ma jedną ważną zaletę: pozwala szybko odpowiedzieć na pytanie, czy w ogóle rozumiemy problem. Jeśli potrafię rozpisać najprostszy wariant, to znaczy, że znam granice zadania i widzę, co dokładnie trzeba policzyć, porównać albo sprawdzić. Potem dopiero myślę o optymalizacji. Z punktu widzenia nauki programowania to bardzo zdrowa kolejność, bo najpierw buduje intuicję, a dopiero potem wydajność. Z tego powodu warto zobaczyć, jak to wygląda na konkretnych zadaniach.
Jak wygląda to na prostych zadaniach
Najłatwiej zrozumieć taki sposób myślenia na przykładach, które pojawiają się na początku nauki programowania. Właśnie tam najczęściej widać, że rozwiązanie proste nie zawsze jest szybkie, ale prawie zawsze jest dobrym punktem wyjścia.
| Problem | Najprostszy sposób | Co z tego wynika |
|---|---|---|
| Szukanie liczby w tablicy | Sprawdzam każdy element po kolei | Łatwe do napisania, działa w czasie liniowym |
| Sprawdzanie duplikatów | Porównuję każdą parę elementów | Proste logicznie, ale szybko robi się kosztowne |
| Wyszukiwanie wzorca w tekście | Przesuwam wzorzec znak po znaku i porównuję fragmenty | Dobry model do zrozumienia problemu, lecz słaby dla dużych danych |
| Wybór najlepszego wariantu | Testuję wszystkie możliwości | Bezpieczne przy małej liczbie opcji, niepraktyczne przy wielu kombinacjach |
Właśnie tu dobrze widać sens prostego podejścia: nie udaję, że znam lepszą metodę, zanim nie rozumiem tej podstawowej. Przykładowo przy wyszukiwaniu wartości w tablicy kod może wyglądać bardzo zwyczajnie:
dla każdego elementu w tablicy:
jeśli element == szukana_wartość:
zwróć "znaleziono"
zwróć "brak wyniku"To nie jest efektowne, ale jest czytelne i łatwe do sprawdzenia. Dla początkującego to często ważniejsze niż elegancja. Kiedy taki szkic już działa, można go sensownie porównać z lepszą wersją i zobaczyć, co naprawdę warto poprawić.
Kiedy prostota zaczyna kosztować za dużo
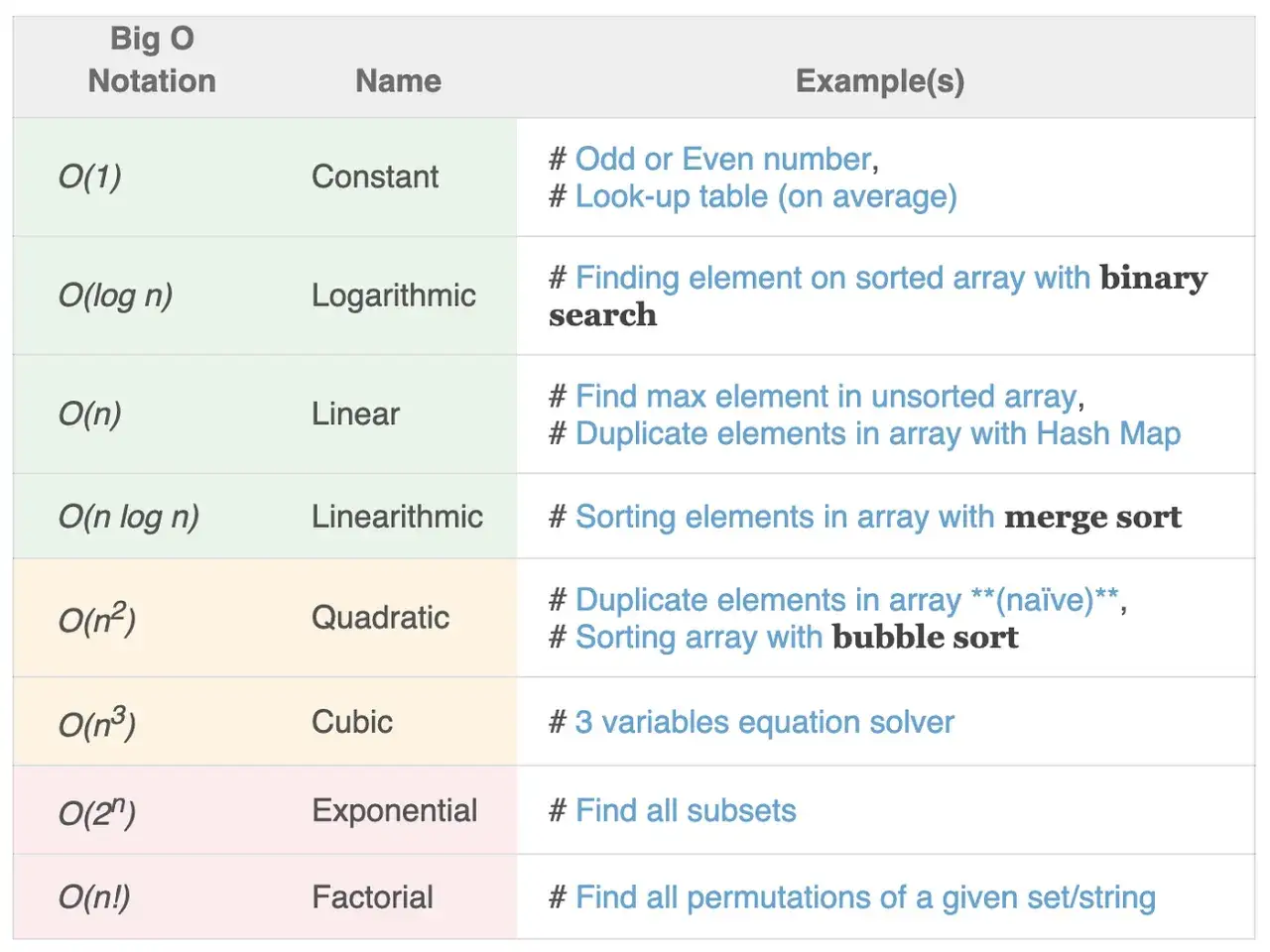
Granica między dobrym początkiem a zbyt wolnym kodem pojawia się wtedy, gdy rośnie liczba danych. Jeśli rozwiązanie ma złożoność O(n^2), to podwojenie wejścia nie oznacza podwojenia pracy, tylko mniej więcej czterokrotny wzrost liczby operacji. Dla 1 000 elementów oznacza to około 1 000 000 porównań, a dla 10 000 już około 100 000 000. Taka różnica szybko robi się odczuwalna, nawet jeśli sam kod wygląda niewinnie.
W praktyce porównuję kilka rzeczy naraz: czas działania, czytelność i łatwość utrzymania. Naiwne rozwiązanie wygrywa, gdy dane są małe albo problem jest jednorazowy. Przegrywa, gdy program ma działać często, na większych zbiorach albo w miejscu, gdzie każda sekunda ma znaczenie. Wtedy zaczynam szukać lepszych narzędzi, na przykład odpowiedniej struktury danych, lepszego sposobu przeszukiwania albo algorytmu o mniejszej złożoności.| Kryterium | Naiwny wariant | Lepsza wersja |
|---|---|---|
| Złożoność czasowa | Często O(n^2) lub O(n·k) | Najczęściej O(n) albo O(n log n) |
| Łatwość zrozumienia | Bardzo duża | Średnia lub niższa |
| Ryzyko błędu | Niskie na starcie | Wyższe, bo logika bywa bardziej złożona |
| Zastosowanie | Małe dane, prototyp, nauka | Duże dane, produkcja, zadania wydajnościowe |
To właśnie dlatego nie traktuję prostego algorytmu jako czegoś gorszego z definicji. Traktuję go jak punkt odniesienia. Najpierw sprawdzam, czy działa. Dopiero potem decyduję, czy jego cena obliczeniowa nie jest zbyt wysoka. Skoro granica jest już jasna, łatwo też wskazać błędy, które początkujący popełniają najczęściej.
Najczęstsze błędy przy takim podejściu
Największy błąd to mylenie prostoty z wystarczalnością. To, że kod działa na małym przykładzie, nie znaczy jeszcze, że będzie dobry dla realnych danych. Na początku nauki programowania to bardzo częste, bo testy robi się zwykle na krótkich tablicach i niewielkich tekstach, a wtedy prawie wszystko wygląda dobrze.
- Brak myślenia o skali - kod przechodzi testy lokalne, ale nie wiadomo, co zrobi przy dziesięciokrotnie większym wejściu.
- Ignorowanie złożoności - rozwiązanie jest poprawne, lecz działa zbyt wolno, bo każdy dodatkowy element dokłada kolejne pętle.
- Optymalizacja na ślepo - ktoś próbuje przyspieszać kod bez zrozumienia, które miejsce naprawdę spowalnia program.
- Przeskakiwanie etapu prostego szkicu - od razu powstaje „sprytna” wersja, której potem nie da się łatwo sprawdzić ani poprawić.
- Brak porównania z wersją bazową - bez prostego wariantu trudno ocenić, czy bardziej złożone rozwiązanie faktycznie coś daje.
W praktyce najrozsądniej jest najpierw napisać wersję, którą sam potrafię wyjaśnić w jednym zdaniu. Jeśli nie umiem tego zrobić, zwykle oznacza to, że jeszcze nie rozumiem problemu wystarczająco dobrze. I właśnie ten moment prowadzi do najważniejszego pytania: jak pracować z prostym pomysłem tak, żeby stał się bazą do lepszego rozwiązania, a nie pułapką.
Jak z prostego pomysłu przejść do lepszego rozwiązania
Najlepiej działa u mnie prosty schemat pracy. Nie zaczynam od szukania ideału, tylko od wersji, która rozwiązuje problem w najkrótszej możliwej formie. Dopiero później sprawdzam, co można skrócić, przyspieszyć albo uprościć w inny sposób. Taka kolejność dobrze się sprawdza zwłaszcza w podstawach programowania, bo uczy myślenia krok po kroku.
- Opisz problem własnymi słowami - jeśli nie potrafisz powiedzieć, co ma robić program, kod będzie przypadkowy.
- Napisz najprostszy działający wariant - bez sprytnych skrótów, ale z poprawną logiką.
- Sprawdź go na małych i większych danych - różnica w zachowaniu bardzo szybko pokazuje, czy zbliża się problem ze skalą.
- Oszacuj złożoność - wystarczy wiedzieć, czy rośnie liniowo, kwadratowo czy jeszcze gorzej.
- Popraw tylko to, co naprawdę boli - najpierw usuń wąskie gardło, a nie przebudowuj całego kodu bez potrzeby.
To podejście oszczędza czas i daje lepszą kontrolę nad jakością rozwiązania. W nauce programowania jest też szczególnie cenne, bo pozwala odróżnić kod, który po prostu działa, od kodu, który działa dobrze także wtedy, gdy wejście przestaje być małe. Jeśli zapamiętasz jedną rzecz, niech będzie taka: prosty algorytm to nie porażka, tylko etap pracy, który często prowadzi do naprawdę dobrego rozwiązania.