Instrukcja switch w Go porządkuje rozgałęzienia, które w dłuższym kodzie szybko zamieniają się w ciężki do czytania łańcuch `if...else if...`. W praktyce to jedno z tych narzędzi, które naprawdę upraszczają logikę, jeśli używa się ich do właściwego problemu. Poniżej pokazuję, jak działa ten mechanizm, czym różni się zwykły switch od type switcha i gdzie początkujący najczęściej popełniają błąd, gdy temat pojawia się pod hasłem golang switch case.
Najważniejsze rzeczy, które warto wiedzieć o switchu w Go
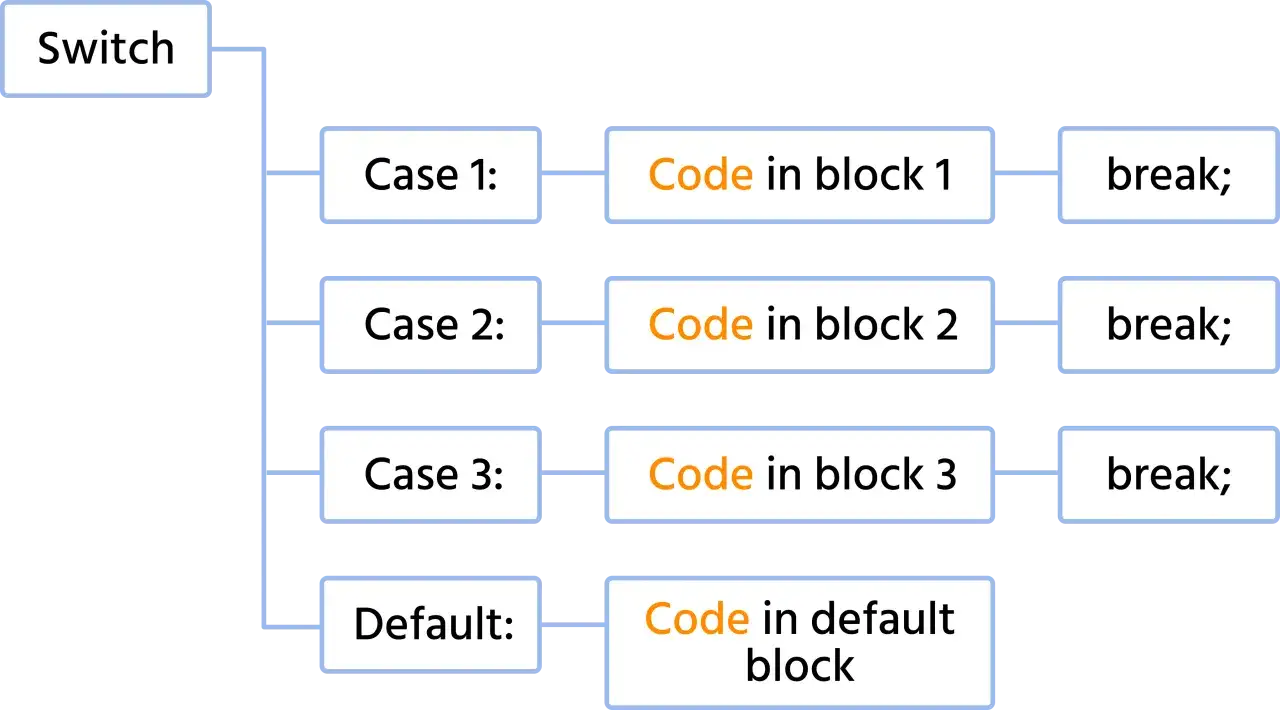
- W Go nie ma automatycznego przechodzenia do następnego `case`, więc na końcu bloku zwykle nie trzeba pisać `break`.
- `switch` może porównywać wartości albo typy, zależnie od tego, jak go zapiszesz.
- Jeden `case` może obsłużyć kilka wartości naraz, jeśli rozdzielisz je przecinkami.
- `default` jest opcjonalny i możesz umieścić go także w środku instrukcji.
- Type switch działa na wartościach interfejsowych i pomaga rozpoznać konkretny typ danych.
- Gdy warunki są złożone albo nakładają się na siebie, `if` bywa czytelniejszy niż `switch`.
Jak działa switch w Go i czym różni się od if
Ja traktuję `switch` jako narzędzie do wyboru jednej z kilku jasno nazwanych dróg. W Go instrukcja ta jest bardziej elastyczna niż w wielu językach z rodziny C: może porównywać nie tylko liczby, ale też napisy, wartości logiczne i, w osobnej odmianie, typy. Najważniejsze jest to, że wyrażenie w `switch` jest obliczane tylko raz, a potem Go sprawdza kolejne `case` od góry do dołu, aż znajdzie pasujący.
To odróżnia `switch` od rozbudowanego `if...else if...`, gdzie zwykle sam piszesz kolejne warunki i pilnujesz ich kolejności. W `switch` ta kolejność nadal ma znaczenie, ale zapis jest bardziej zwarty i lepiej pokazuje, że chodzi o wybór jednej z kilku kategorii, a nie o skomplikowaną logikę.
| Forma | Co porównuje | Kiedy użyć |
|---|---|---|
| Expression switch | Wartości | Kody statusu, kategorie, proste klasyfikacje |
| Switch bez wyrażenia | Warunki logiczne | Progi, zakresy, kilka niezależnych testów boolowskich |
| Type switch | Typy interfejsów | Praca z `any`, `interface{}` i różnymi implementacjami |
W praktyce ta różnica jest ważniejsza niż sama składnia. Kiedy widzę `switch`, od razu wiem, że autor chce opisać zestaw rozłącznych przypadków, a nie zbudować matematycznie złożonego warunku. Dzięki temu kod czyta się szybciej, a to zwykle przekłada się na mniej błędów przy późniejszej zmianie logiki.
Składnia, którą warto znać od razu
W Go masz trzy użyteczne warianty: switch z wyrażeniem, switch bez wyrażenia oraz switch z krótką instrukcją przed warunkiem. Ten ostatni bywa szczególnie wygodny, bo pozwala przygotować lokalną zmienną tylko na potrzeby samej instrukcji.
switch n := len(users); n {
case 0:
return "brak użytkowników"
case 1:
return "jeden użytkownik"
default:
return "więcej niż jeden"
}Ten zapis ma dwie zalety. Po pierwsze, `n` żyje tylko wewnątrz `switch`, więc nie zaśmiecasz zewnętrzego zakresu. Po drugie, od razu widać, że decyzja dotyczy jednej konkretnej liczby, a nie całej serii warunków pobocznych.
Jeśli potrzebujesz zakresów albo kilku niezależnych porównań, możesz pominąć wyrażenie po `switch` i oprzeć logikę na warunkach boolowskich:
switch {
case score >= 90:
return "celujący"
case score >= 75:
return "dobry"
case score >= 50:
return "dopuszczający"
default:
return "niedostateczny"
}To jest bardzo czytelny wzorzec. Nie próbuję wtedy wciskać wszystkiego w jedną zbitkę `if...else if...`; zamiast tego układam warunki od najbardziej restrykcyjnego do najbardziej ogólnego. Gdy ta kolejność ma znaczenie, `switch` pokazuje je bez zbędnego szumu. A skoro już masz składnię w ręku, warto zobaczyć, jak wygląda to na realnych przykładach.
Praktyczne przykłady z codziennego kodu
Najczęściej używam `switch` tam, gdzie dane dają się sensownie pogrupować. W projektach webowych to zwykle statusy HTTP, typy komunikatów, poziomy dostępu, etapy procesu albo progi liczbowe. Właśnie wtedy `switch` daje największy zwrot: kod robi się krótszy, a intencja staje się oczywista.
Kody statusu HTTP
func opisStatusu(code int) string {
switch code {
case 200, 201, 204:
return "sukces"
case 400, 401, 403, 404:
return "błąd po stronie klienta"
case 500, 502, 503:
return "błąd po stronie serwera"
default:
return "inny status"
}
}Ten przykład pokazuje jedną z mocniejszych stron Go: w jednym `case` możesz zebrać kilka wartości oddzielonych przecinkami. To zwykle czytelniejsze niż powielanie tych samych akcji w kilku osobnych warunkach. Dla mnie to ważny sygnał, że autor kodu myśli kategoriami, a nie tylko mechanicznie porównuje liczby.
Przeczytaj również: Kotlin od Zera - Jak zacząć i uniknąć błędów?
Progi i klasyfikacje
func ocenaWyniku(score int) string {
switch {
case score >= 90:
return "bardzo dobry"
case score >= 70:
return "dobry"
case score >= 50:
return "dostateczny"
default:
return "niedostateczny"
}
}To dobry wzorzec wszędzie tam, gdzie decyzja zależy od zakresu. Zwróć uwagę, że warunki są uporządkowane od najwyższego progu do najniższego. Gdyby odwrócić kolejność, pierwsza pasująca gałąź mogłaby przechwycić wynik wcześniej, niż chciałeś. Właśnie dlatego kolejność w takim `switch` ma znaczenie praktyczne, a nie tylko estetyczne.
W takich przykładach switch bywa lepszy niż mapa, bo nie tylko zwraca wartość, ale też pozwala od razu wykonać dodatkową logikę. Jeśli po przeczytaniu tego fragmentu zastanawiasz się, co z sytuacjami, w których typ sam decyduje o zachowaniu, odpowiedź daje type switch.
Type switch, czyli decyzja na podstawie typu
Type switch przydaje się wtedy, gdy pracujesz z wartością interfejsową i chcesz sprawdzić, czym ona naprawdę jest. To narzędzie do obsługi różnych implementacji albo do bezpiecznego rozpoznawania danych przychodzących z zewnątrz. W Go zapis wygląda podobnie do zwykłego `switch`, ale zamiast wartości porównujesz typy.
func opisz(v any) string {
switch v := v.(type) {
case nil:
return "nil"
case int:
return "liczba całkowita"
case string:
return "napis: " + v
case []byte:
return "tablica bajtów"
default:
return "inny typ"
}
}W tym wariancie zmienna po lewej stronie `:=` przyjmuje typ dopasowany do konkretnego `case`. To wygodne, bo wewnątrz gałęzi możesz od razu używać metod i operacji właściwych dla tego typu, bez dodatkowych rzutowań. W praktyce oszczędza to sporo kodu i ogranicza ryzyko błędów związanych z niepotrzebnym type assertion.
Jest tu jednak ważne ograniczenie: fallthrough nie działa w type switchu. Jeśli więc planujesz „spuszczać” sterowanie do kolejnej gałęzi, musisz od razu zmienić podejście. Dla mnie to rozsądne ograniczenie, bo type switch ma rozpoznawać typ, a nie symulować bardziej złożony silnik przepływu sterowania. I właśnie o takim przepływie warto teraz powiedzieć wprost.
Fallthrough, break i pułapki, które psują czytelność
W Go nie ma automatycznego przechodzenia do następnego `case`. To jedna z tych rzeczy, które wielu programistów łapią po pierwszym kontakcie z językiem. Oznacza to, że na końcu gałęzi zwykle nie musisz pisać `break`, bo wykonanie i tak kończy się po zakończeniu bloku.
Jeśli chcesz wymusić przejście do kolejnego `case`, służy do tego `fallthrough`. Ale używa się go ostrożnie i tylko w expression switchu, jako ostatniego niepustego polecenia w gałęzi. W type switchu jest niedozwolony, więc tam temat w ogóle odpada.
Są też inne pułapki, które widzę w kodzie początkujących:
- zbyt wiele warunków w jednym `switch`, przez co logika zaczyna przypominać mały interpreter;
- próba używania `switch` do przypadków, które lepiej opisać mapą lub osobnymi funkcjami;
- układanie warunków bez uwzględnienia kolejności, co w `switch {}` może zmienić wynik;
- zostawianie `fallthrough` tylko dlatego, że ktoś pamięta składnię z C;
- mylenie `break` z koniecznością zamknięcia `case`, choć w Go nie jest to potrzebne.
Jeśli `switch` znajduje się wewnątrz pętli i chcesz wyjść nie tylko z samego `switch`, ale także z całej pętli, przydaje się etykieta i `break` do tej etykiety. To już bardziej zaawansowany przypadek, ale właśnie on pokazuje, że w Go `switch` i `break` mają konkretne, precyzyjne znaczenie, a nie są tylko ozdobą składni. Gdy rozumiesz te ograniczenia, łatwiej ocenić, kiedy `switch` naprawdę jest najlepszym wyborem.
Jak pisać switch, który zostaje czytelny w większym projekcie
Moje praktyczne kryterium jest proste: jeśli `switch` opisuje jedną oś decyzji, zostawiam go; jeśli zaczyna mieszać kilka niezależnych reguł, rozbijam go na mniejsze części. W większym kodzie to robi ogromną różnicę, bo później ktoś inny ma od razu zobaczyć, co jest kryterium wyboru.
- Utrzymuj `case` krótkie i jednofunkcyjne.
- Grupuj powiązane wartości w jednym `case`, zamiast powtarzać te same akcje.
- Gdy warunek opiera się na przedziałach, użyj switcha bez wyrażenia.
- Gdy decyzja zależy od typu interfejsu, wybierz type switch, a nie kaskadę rzutowań.
- Jeśli logika rośnie do wielu stron, rozważ osobne funkcje albo mapę handlerów.
W praktyce `switch` najlepiej działa wtedy, gdy można go przeczytać jednym spojrzeniem. Jeśli muszę analizować go dłużej niż zwykłą pętlę `if`, to zwykle znak, że projektuję go zbyt ambitnie. Najlepszy kod nie pokazuje wszystkich możliwości języka naraz, tylko wybiera te, które naprawdę upraszczają decyzję.
Jeśli masz zapamiętać tylko jedną rzecz, niech będzie to ta: switch w Go ma porządkować wybór, a nie ukrywać złożoną logikę. Gdy używasz go do wartości, progów i typów w sposób zgodny z intencją języka, kod staje się krótszy, bezpieczniejszy i łatwiejszy do utrzymania. A to właśnie w Go zwykle daje najlepszy efekt.