Metoda Aggregate w C# to narzędzie do budowania własnych agregacji na kolekcjach: od prostego zliczania, przez łączenie tekstu, po tworzenie bardziej złożonych podsumowań danych. W praktyce jest przydatna wtedy, gdy standardowe operatory LINQ, takie jak Sum czy Count, są zbyt wąskie. Pokażę, jak działa, jak czytać jej przeciążenia i kiedy naprawdę ma sens w kodzie aplikacji webowej.
Najważniejsze informacje o agregacji w LINQ
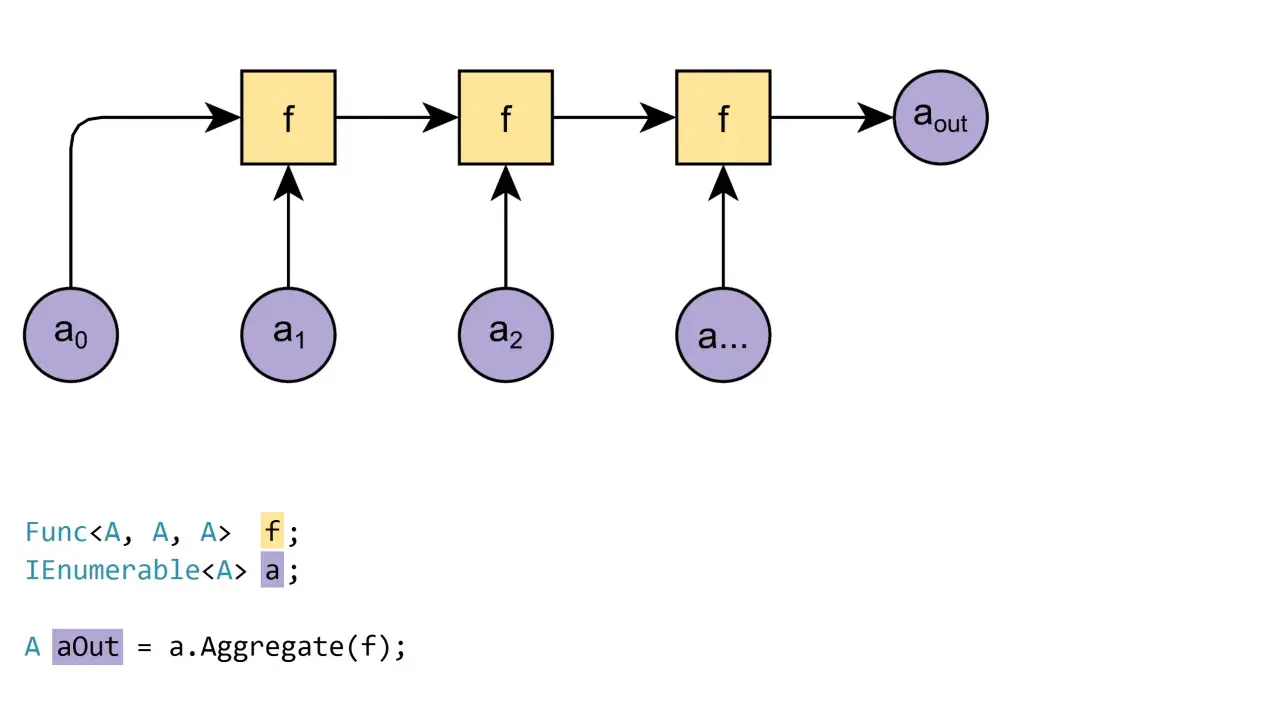
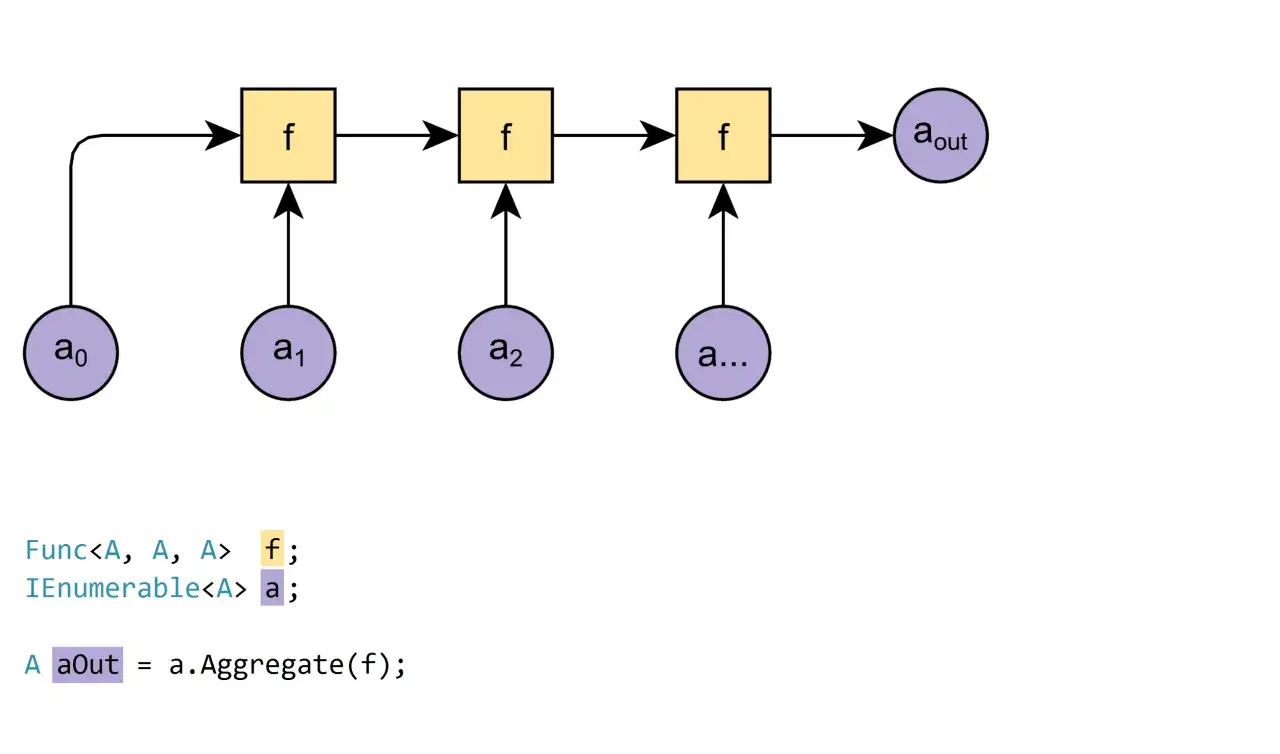
- Aggregate przechodzi po sekwencji jednokrotnie i utrzymuje stan akumulatora.
- Ma 3 przeciążenia, a najpraktyczniejsze z nich przyjmują seed, czyli wartość początkową.
- Bez seeda metoda na pustej kolekcji rzuca InvalidOperationException.
- Z seedem możesz liczyć, sklejać tekst, budować obiekty wynikowe i tworzyć własne statystyki.
- Do prostych zadań liczbowych zwykle lepsze są wyspecjalizowane metody, np.
Sum,Count,MaxlubAverage. - W zapytaniach do bazy danych zawsze sprawdzaj, czy provider faktycznie potrafi przetłumaczyć agregację po swojej stronie.
Co robi metoda Aggregate i kiedy naprawdę warto po nią sięgnąć
Aggregate działa jak programistyczny odpowiednik reduce albo fold: bierze kolekcję, trzyma bieżący stan i aktualizuje go dla każdego elementu. Ja traktuję tę metodę jako sposób na wyrażenie logiki „weź całość i zredukuj ją do jednego wyniku”, ale bez zamykania się tylko w liczbach.
To ważne rozróżnienie. Gdy chcesz po prostu policzyć sumę, średnią albo liczbę elementów, masz gotowe operatory LINQ. Gdy wynik ma być czymś bardziej złożonym niż pojedyncza liczba, Aggregate pokazuje swoją moc: możesz budować tekst, obiekt z podsumowaniem, stan koszyka, a nawet reguły biznesowe oparte na całej sekwencji.
W kodzie webowym najczęściej widzę ją przy raportach, podsumowaniach zamówień, walidacji zbiorczej i transformacji danych wejściowych do jednego sensownego wyniku. Żeby dobrze to wykorzystać, trzeba najpierw rozróżnić trzy warianty metody i ich konsekwencje.
Jak czytać trzy przeciążenia metody
Dokumentacja .NET pokazuje trzy przeciążenia Aggregate, ale w praktyce najłatwiej myśleć o nich jak o trzech poziomach kontroli nad stanem pośrednim. Różnica między nimi ma znaczenie nie tylko składniowe, ale też semantyczne.
| Wariant | Co robi | Kiedy użyć | Na co uważać |
|---|---|---|---|
Aggregate(source, func) |
Używa pierwszego elementu jako stanu początkowego | Gdy kolekcja nie bywa pusta i chcesz startować od danych wejściowych | Na pustej sekwencji rzuci wyjątek |
Aggregate(source, seed, func) |
Zaczyna od wskazanego seeda i aktualizuje stan dla każdego elementu | Gdy chcesz bezpiecznie obsłużyć pustą kolekcję albo liczyć od zera | Seed musi być logicznie neutralny dla operacji |
Aggregate(source, seed, func, resultSelector) |
Najpierw buduje stan, potem przekształca go do finalnego wyniku | Gdy wynik pośredni i końcowy nie są tym samym typem | Łatwo przekombinować, jeśli rezultat da się wyrazić prościej |
Najważniejszy detal jest prosty: w wersjach z seedem przechodzisz po sekwencji dokładnie raz, a wynik końcowy zależy od tego, jak dobierzesz stan początkowy. W wersji bez seeda akumulator startuje od pierwszego elementu, więc brak danych wejściowych kończy się błędem. To właśnie dlatego w kodzie produkcyjnym częściej wybieram wariant z seedem.
Jeśli chcesz to zobaczyć na konkretnych przykładach, teraz przejdziemy od teorii do krótkich, praktycznych przypadków.
Przykłady, które pokazują różnicę między seedem a resultSelector
Najłatwiej zrozumieć Aggregate na przykładach, bo sama sygnatura bywa cięższa niż rzeczywiste użycie. Dwa poniższe przypadki dobrze pokazują, po co istnieje seed i kiedy przydaje się resultSelector.
Zliczanie elementów spełniających warunek
int[] numbers = { 4, 8, 8, 3, 9, 0, 7, 8, 2 };
int evenCount = numbers.Aggregate(
0,
(total, next) => next % 2 == 0 ? total + 1 : total);
Console.WriteLine(evenCount); // 6To przykład bardziej edukacyjny niż praktyczny, bo do samego zliczania parzystych liczb lepszy będzie zwykły Count. Mimo to ten kod świetnie pokazuje logikę: seed = 0, a każda kolejna liczba albo zwiększa licznik, albo nie zmienia stanu. Z tego samego wzorca korzysta się później przy dużo bardziej złożonych podsumowaniach.
Składanie tekstu bez pętli i bez niepotrzebnych alokacji
using System.Text;
string[] names = { "Ada", "Michał", "Ola" };
string csv = names.Aggregate(
new StringBuilder(),
(builder, name) =>
{
if (builder.Length > 0)
{
builder.Append(", ");
}
builder.Append(name);
return builder;
},
builder => builder.ToString());
Console.WriteLine(csv); // Ada, Michał, OlaTutaj resultSelector robi realną robotę. Wewnętrzny stan jest oparty na StringBuilder, ale końcowy wynik ma być zwykłym string. To dobra technika, gdy zależy ci na wydajniejszym składaniu tekstu i nie chcesz doklejać kolejnych fragmentów operatorem +. W aplikacjach webowych taki wzorzec przydaje się częściej, niż wielu osobom się wydaje, zwłaszcza przy generowaniu treści, logów albo prostych raportów.
Przeczytaj również: C++ - Co to jest, jak działa i czy warto się go uczyć?
Wybór najdłuższego elementu z jednoczesnym formatowaniem wyniku
string[] fruits = { "apple", "mango", "orange", "passionfruit", "grape" };
string longestName = fruits.Aggregate(
"banana",
(longest, next) => next.Length > longest.Length ? next : longest,
fruit => fruit.ToUpperInvariant());
Console.WriteLine(longestName); // PASSIONFRUITTen przykład pokazuje pełen sens trzeciego przeciążenia. Stan pośredni służy do porównywania długości, ale wynik końcowy ma już inną formę. Dzięki temu nie musisz rozdzielać logiki na dwa kroki, jeśli końcowy format wyniku jest prosty i przewidywalny. Z takim podejściem łatwiej też przejść do bardziej biznesowych scenariuszy, w których Aggregate buduje nie tekst, lecz własny obiekt.
Jak zbudować własne podsumowanie danych
Najciekawsze zastosowanie tej metody zaczyna się wtedy, gdy wynik ma kilka pól, a nie jedno. Ja najczęściej widzę to w raportach sprzedaży, koszykach zakupowych i analizach danych wejściowych z formularzy. Zamiast robić trzy osobne przebiegi po kolekcji, możesz utrzymywać jeden spójny stan.
Przykład: chcesz policzyć liczbę elementów, ich sumę i średnią. W prostym wariancie możesz zbudować mały obiekt akumulatora, a na końcu przekształcić go do gotowego raportu.
public record OrderStats(int Count, decimal Sum);
decimal[] totals = { 129.99m, 49.50m, 210.00m };
var stats = totals.Aggregate(
new OrderStats(0, 0m),
(acc, value) => new OrderStats(acc.Count + 1, acc.Sum + value),
acc => new
{
acc.Count,
acc.Sum,
Average = acc.Count == 0 ? 0 : acc.Sum / acc.Count
});
Console.WriteLine(stats.Count);
Console.WriteLine(stats.Sum);
Console.WriteLine(stats.Average);To już nie jest sztuczka dla sztuczki. W takim układzie stan pośredni jest czytelny, a finalny wynik może mieć dokładnie taki kształt, jakiego potrzebuje warstwa prezentacji lub API. Jeśli akumulator zaczyna rozrastać się do kilkunastu pól, wtedy zwykle radzę się zatrzymać i sprawdzić, czy nie lepiej wydzielić osobnej klasy albo metody pomocniczej. Sam Aggregate nadal działa, ale kod może stać się zbyt gęsty.
Skoro już widać, jak tworzyć własne wyniki, czas odpowiedzieć na praktyczne pytanie: kiedy lepiej wybrać coś prostszego niż ta metoda.
Kiedy lepsze są Sum, Count, Max, Min lub Average
W mojej ocenie Aggregate nie jest domyślnym wyborem do wszystkiego. To narzędzie precyzyjne, ale nie zawsze najbardziej czytelne. Jeśli standardowy operator robi dokładnie to, czego potrzebujesz, zwykle warto wziąć standardowy operator.
| Potrzeba | Lepiej użyć | Dlaczego |
|---|---|---|
| Dodanie liczb | Sum |
Jest krótszy, czytelniejszy i jasno komunikuje intencję |
| Policzenie elementów | Count |
Nie musisz ręcznie utrzymywać licznika |
| Wybranie minimum lub maksimum |
Min / Max
|
Lepsza ekspresja zamiaru niż własna logika porównania |
| Obliczenie średniej | Average |
Unikasz własnej obsługi sumy i dzielenia przez zero |
| Własna reguła, własny stan, wynik wielopolowy | Aggregate |
Tu metoda pokazuje pełnię możliwości |
Ta tabela dobrze oddaje zasadę, którą stosuję w code review: jeśli ktoś używa Aggregate do zwykłego sumowania, pytam, czy Sum nie byłby po prostu lepszy. Nie chodzi o stylistyczny pedantyzm. Chodzi o to, żeby osoba czytająca kod po trzech miesiącach od razu wiedziała, co ma się stać. W tym miejscu naturalnie pojawia się temat pułapek, bo właśnie tam takie decyzje najczęściej się wykładają.
Najczęstsze pułapki przy pracy z LINQ i providerami
Najbardziej klasyczny błąd to użycie wariantu bez seeda na pustej sekwencji. Wtedy dostajesz InvalidOperationException, bo metoda nie ma od czego zacząć. Jeśli dane mogą być puste, seed nie jest opcją „na wszelki wypadek”, tylko koniecznością.
- Zbyt skomplikowany akumulator - jeśli w lambdzie dzieje się za dużo, przenieś logikę do osobnej metody albo obiektu.
- Mutowanie stanu bez kontroli - da się to zrobić, ale tylko świadomie. Przy współdzielonych referencjach łatwo o trudny do wykrycia błąd.
- Użycie `Aggregate` tam, gdzie wystarczy prostszy operator - kod staje się wtedy cięższy bez realnego zysku.
- Założenie, że każde zapytanie przetłumaczy się do SQL - w providerach LINQ wsparcie zależy od konkretnego dostawcy i kształtu zapytania.
- Brak testu na pustych danych - szczególnie ważny w API, gdzie brak rekordów jest normalnym scenariuszem, a nie wyjątkiem.
W przypadku EF Core albo innych providerów bazodanowych zawsze sprawdzam, czy dana agregacja faktycznie wykonuje się po stronie serwera. Dokumentacja .NET jasno pokazuje, że nie każdy operator i nie każda forma zapytania ma identyczne wsparcie translacji, więc warto to zweryfikować na realnym providerze, a nie zakładać z góry. To drobny nawyk, który oszczędza sporo czasu przy debugowaniu wydajności.
Po przejściu przez te błędy zostaje już tylko jedna rzecz: jak pisać takie agregacje, żeby po miesiącu nadal były zrozumiałe.
Jak pisać agregacje, które da się utrzymać po miesiącu
Jeśli miałbym streścić praktykę w kilku zasadach, wyglądałoby to tak: seed ma być neutralny, akumulator ma być mały, a intencja ma być widoczna bez zgadywania. To właśnie odróżnia dobry kod od kodu, który tylko „działa”.
- Dobieraj seed tak, aby naturalnie pasował do operacji, np.
0dla zliczania, pusty builder dla tekstu, pusty stan dla statystyk. - Jeśli wynik końcowy ma inny typ niż stan pośredni, użyj
resultSelectorzamiast mieszać wszystko w jednej lambdzie. - Nie bój się wydzielić pomocniczego typu, gdy akumulator zaczyna mieć więcej niż 2-3 pola.
- Testuj trzy scenariusze: kolekcję pustą, jednopunktową i typowy zestaw danych.
- Do prostych zadań wybieraj prostsze operatory LINQ, nawet jeśli
Aggregatedałoby się tam wcisnąć.
W praktyce najlepsze użycie tej metody polega nie na imponowaniu składnią, tylko na skróceniu i uporządkowaniu logiki, która inaczej rozlałaby się po pętlach, zmiennych pomocniczych i warunkach. Gdy zapiszesz sobie taki stan w jednym miejscu, kod zwykle staje się łatwiejszy do przetestowania i mniej podatny na przypadkowe regresje.
Co warto zapamiętać, zanim użyjesz Aggregate w produkcji
Najkrócej mówiąc, Aggregate jest świetne wtedy, gdy chcesz z kolekcji zbudować coś własnego, a nie tylko policzyć albo zsumować dane. W prostych scenariuszach bywa zbędne, ale w bardziej złożonych agregacjach pozwala wyrazić zamiar w jednym, zwartym wywołaniu.
Jeżeli mam zostawić jedną praktyczną wskazówkę, to tę: najpierw zapytaj siebie, czy wynik nie da się opisać gotowym operatorem LINQ. Jeśli odpowiedź brzmi „nie”, wtedy Aggregate jest dokładnie tym narzędziem, którego szukasz. A jeśli wynik zależy od kilku pól, kilku etapów i końcowego przekształcenia, ta metoda często okazuje się czystsza niż ręcznie pisana pętla.
W projektach webowych najwięcej zyskuje się nie na samej „magii LINQ”, tylko na konsekwentnym wybieraniu narzędzia do problemu. I właśnie dlatego dobrze opanowana agregacja w C# przydaje się zarówno początkującym, jak i osobom, które budują już większe aplikacje i chcą pisać kod krótszy, ale nadal czytelny.